원-핫 인코딩
1. 원-핫 인코딩이란?
표현하고 싶은 단어의 인덱스에 1의 값, 나머지 인덱스에는 0을 부여하는 벡터 표현 방식이며, 이렇게 표현된 벡터를 원-핫 벡터라고 부름
2. 원-핫 인코딩 프로세스

3. 원-핫 인코딩의 한계
- 단어 개수가 늘어날 수록 벡터를 저장하기 위한 공간이 늘어남(저장 공간 및 연산 측면에서 비효율)
- 단어의 유사도를 표현할 수 없음
4. 한국어 문장을 원-핫 벡터로 생성하는 예시
문장: 오늘 아침 커피는 맛있습니다.
- 한국어 형태소 분석을 위한 konlpy 설치
# 형태소 분석을 위한 konlpy 설치
!pip install konlpy
- 형태소 분석기로 문장 토큰화
# 형태소 분석기로 문장을 형태소 단위로 나눔(문장 토큰화)
from konlpy.tag import Okt
okt = Okt()
token = okt.morphs("오늘 아침 커피는 맛있습니다")
print(token)
- 각 토큰에 인덱스 부여
word2index = {}
for voca in token:
if voca not in word2index.keys():
word2index[voca] = len(word2index)
print(word2index)
- 원-핫 벡터를 생성하는 함수 정의
# 토큰을 입력하면 해당 토큰에 대한 원-핫 벡터를 생성하는 함수
def one_hot_encoding(word, word2index):
one_hot_vector = [0]*(len(word2index))
index = word2index[word]
one_hot_vector[index] = 1
return one_hot_vector
- 단어 입력 후 출력 확인
one_hot_encoding("커피",word2index)
- 전체 원-핫 벡터 확인
for i in word2index:
token_vector = one_hot_encoding(i, word2index)
print(i, token_vector)
워드 임베딩(Word Embedding)
- 워드 임베딩은 단어를 밀집 표현으로 변환해 벡터로 표현하는 기법
- 워드 임베딩 과정에서 나온 밀집 벡터를 임베딩 벡터(embedding vector)라고 함
- 워드 임베딩 방법론에는 LSA, Word2Vec, Fasttext, Glove 등이 있음
- 파이토치의 워드 임베딩 도구는 nn.embedding()이 있으며 단어를 랜덤한 값을 가지는 밀집 벡터로 변환한 뒤, 인공 신경망의 가중치를 학습하는 것과 비슷하게 단어 벡터를 학습하는 방법을 사용함
| 희소 표현(Sparse Representation) | 밀집 표현(Dense Representation) |
| - 원-핫 인코딩 처럼 벡터나 행렬의 값이 대부분 0으로 표현 - 단어의 개수가 늘어나면 벡터의 차원이 커지는 단점 - 단어간 유사도 표현 불가(자연어 처리에서 치명적) |
- 0과 1만 가진 값이 아니라 실수 값을 가짐 - 벡터의 차원을 단어 집합 크기로 상정하지 않음 - 사용자가 설정한 값으로 모든 단어의 벡터 표현을 맞춤 |
| ex) 강아지 = [00001000...] | ex) 강아지 = [0.2, 1.8, 1.1, -2.1....] |
| 원-핫 벡터 | 임베딩 벡터 | |
| 차원 | 고차원(단어 집합의 크기) | 저차원 |
| 다른 표현 | 희소 벡터의 일종 | 밀집 벡터의 일종 |
| 표현 방법 | 수동 | 훈련 데이터로부터 학습 |
| 값의 타입 | 1과 0 | 실수 |
워드투벡터(Word2Vec)
단어간 유사도를 반영할 수 있도록 단어의 의미를 벡터화 하는 방법 중 하나
단어의 의미가 벡터화 되면 다음과 같은 연산 가능
ex) 전화기 + 컴퓨터 = 스마트폰
1. 희소 표현(Sparse Representation)
- 벡터나 행렬의 값이 대부분 0으로 표현되는 방법
2. 분산 표현(Distribued Representation)
- 단어간 유사성을 표현할 수 없는 희소 표현의 단점을 해결하기 위한 표현 방법
- '비슷한 위치에서 등장하는 단어들은 비슷한 의미를 가진다' 라는 분포 가설을 가정함
- 분산 표현으로 표현된 벡터들은 벡터의 차원이 단어 집합의 크기일 필요가 없어 벡터의 차원이 상대적으로 저차원으로 줄어듬
- 분산 표현의 대표적인 학습 방법이 워드투벡터 임
3. 워드투벡터의 방식
- CBOW(Continuous Bag of Words) : 주변에 있는 단어를 가지고 중간에 있는 단어를 예측
- Skip-Gram : 중간에 잇는 단어로 주변 단어를 예측
- 워드투벡터는 주로 Skip-Gram + 네거티브 샘플링을 사용
4. 네거티브 샘플링(Negative Sampling)
- Word2Vec 모델의 단점은 속도, 단어 집합의 크기가 수백만에 달하면 굉장히 무거워짐
- 이를 해결하기 위해 랜덤으로 주변 단어가 아닌 상관없는 단어들의 일부를 가져와 마지막 단계를 이진 분류 문제로 수행
- 연산량에 있어 매우 효율적
글로브(Global Vecors for Word Representation, GloVe)
- 카운트 기반과 예측 기반을 모두 사용
- 2014년 스탠포드 대학에서 개발
- 카운트 기반의 LSA(Latent Semantic Analysis)와 예측 기반의 Word2Vec의 단점을 보완하기 위한 목적으로 개발
- 현재까지 Word2Vec과 GloVe 중 어떤 것이 더 뛰어나다고 말하기 어려움
| LSA | Word2Vec |
| 각 간어의 빈도수를 카운트한 행렬이라는 전체적 통계정보를 입력으로 받아 차원을 축소하여 잠재된 의미를 예측 | 실제값과 예측값에 대한 오차를 손실함수를 통해 줄여나가며 학습하는 예측 기반 방법론 |
| 단점: 코퍼스의 전체적인 통계 정보를 고려하지만 왕:남자 = 여왕: ? 같은 단어 의미의 유추 작업에는 성능이 떨어짐 |
단점: 유추 작업은 LSA보다 뒤어나지만, 임베딩 벡터가 윈도우 크기 내의 주변단어들만 고려하기 때문에 코퍼스의 전체적인 통계 정보를 반영하지 못함 |
파이토치의 nn.Embedding()
파이토치에서 임베딩 벡터를 사용하는 방법은 크게 두 가지로 구성
방법 1. 임베딩 층을 만들어 훈련 데이터로부터 처음부터 임베딩 벡터를 학습
방법 2. 미리 사전에 훈련된 임베딩 벡터를 가져와 사용
방법 1. 처음부터 임베딩 벡터를 학습하는 방법
# 임의의 문장으로 단어 집합 생성 및 단어에 정수 부여
train_data = 'you need to know how to code'
# 중복을 제거한 단어들의 집합인 단어 집합 생성.
word_set = set(train_data.split())
# 단어 집합의 각 단어에 고유한 정수 맵핑.
vocab = {tkn: i+2 for i, tkn in enumerate(word_set)}
vocab['<unk>'] = 0
vocab['<pad>'] = 1# nn.Embedding()을 사용해 학습 가능한 임베딩 테이블 생성
# nn.Embedding의 인자
# num_embeddings : 임베딩을 할 단어들의 개수. 다시 말해 단어 집합의 크기
# embedding_dim : 임베딩 할 벡터의 차원입니다. 사용자가 정해주는 하이퍼파라미터
# padding_idx : 선택적으로 사용하는 인자입니다. 패딩을 위한 토큰의 인덱스
import torch.nn as nn
embedding_layer = nn.Embedding(num_embeddings=len(vocab),
embedding_dim=3,
padding_idx=1)print(embedding_layer.weight)
방법 2. 토치텍스트를 사용한 사전 훈련된 워드 임베딩(Pretrained Word Embedding)
토치 텍스트는 아래와 같은 영어 단어들의 사전 훈련된 임베딩 벡터를 제공
- fasttext.en.300d
- fasttext.simple.300d
- glove.42B.300d
- glove.840B.300d
- glove.twitter.27B.25d <== 이넘을 사용
- glove.twitter.27B.50d
- glove.twitter.27B.100d
- glove.twitter.27B.200d
- glove.6B.50d
- glove.6B.100d
- glove.6B.200d
- glove.6B.300d
IMDB 리뷰 데이터에 존재하는 단어들을 토치텍스트가 제공하는 사전 훈련된 임베딩 벡터의 값으로 초기화 예
- IMDB 데이터 준비
# 도구 임포트
from torchtext.legacy import data, datasets
# Text와 Label 객체 정의
TEXT = data.Field(sequential=True, batch_first=True, lower=True)
LABEL = data.Field(sequential=False, batch_first=True)
# 데이터 준비
# torch.legacy.datasets를 사용해 IMDB 데이터셋 다운로드 및 학습 데이터셋과 테스트 데이터셋으로 나눔
trainset, testset = datasets.IMDB.splits(TEXT, LABEL)
# 훈련 데이터의 샘플 갯수 확인
print('훈련 데이터의 크기 : {}' .format(len(trainset)))
# >>> 훈련 데이터의 크기 : 25000
# 훈련 데이터의 첫번째 샘플 출력
print(vars(trainset[0]))
# >>> {'text': ['paul', 'hennessy', 'and', 'his', 'wife,', 'cate', 'must', 'deal', 'with', 'their', 'two', 'teenage', 'daughters', 'and', 'weird', 'son...but', 'after', 'the', 'untimely', 'passing', 'of', 'john', 'ritter,', 'the', 'show', 'became', 'more', 'about', 'coping', 'with', 'the', 'loss', 'of', 'a', 'loved', 'one...<br', '/><br', '/>i', 'found', 'this', 'show,', 'passing', 'through', 'the', 'channels', 'one', 'afternoon', 'and', 'i', 'have', 'to', 'say', 'i', 'was', 'laughing', 'myself', 'till', 'my', 'ribs', 'ached,', 'simply', 'at', 'the', 'range', 'of', 'characters;', 'the', 'witty', 'lines', 'and', 'the', 'situation', 'paul', 'would', 'find', 'himself', 'dealing', 'mostly', 'with', 'his', 'daughters...from', 'then', 'on,', 'i', 'caught', 'the', 'rest', 'of', 'the', 'show', 'when', 'i', 'was', 'free', 'and', 'i', 'have', 'to', 'say', 'the', 'writing', 'was', 'very', 'good..but', 'then', 'i', 'read', 'about', 'john', "ritter's", 'death...shortly', 'afterwards', 'i', 'watched', "'goodbye'", 'part', '2', 'and', 'i', 'have', 'to', 'say', 'i', 'was', 'nearly', 'in', 'tears,', 'watching', 'the', 'emotions', 'of', 'the', 'characters,', 'losing', 'a', 'loved', 'one...how', 'rory', 'punches', 'a', 'wall', 'in', 'anger', 'and', 'frustration...how', 'cate', 'deals', 'with', 'having', 'to', 'sleep', 'in', 'her', 'bed', 'all', 'alone....briget', 'and', 'kerry', 'talking', 'about', 'what', 'they', 'should', 'have', 'done.<br', '/><br', '/>but', 'the', 'show', 'does', 'move', 'on,', 'bringing', 'with', 'it', 'jim', 'egan', 'and', 'cj', 'barnes', 'who', 'provide', 'great', 'laughs,', 'as', "cate's", 'father', 'tries', 'to', 'protect', 'his', 'family', 'and', 'give', "'man", 'issue', "talks'", 'to', 'rory...but', 'the', 'true', 'gem', 'is', 'cj...who', 'is', 'absolutely', 'hilarious', 'as', 'the', 'wild', 'cousin.<br', '/><br', '/>it', 'will', 'always', 'be', 'john', "ritter's", 'masterpiece.'], 'label': 'pos'}
- 토치텍스트의 glove.twitter.27B.25d(사전 훈련된 임베딩 벡터)를 불러와 IMDB 리뷰 데이터의 단어를 초기화
# 도구 임포트
import torch
import torch.nn as nn
from torchtext.vocab import GloVe
# Field 객체의 build_vocab을 통해 사전 훈련된 임베딩 벡터 다운 가능
# max_size : 단어 집합의 크기 제한, min_freq : 등장 빈도수가 10번 이상인 단어만 허용
TEXT.build_vocab(trainset, vectors=GloVe(name='twitter.27B', dim=25), max_size=10000, min_freq=10)
LABEL.build_vocab(trainset)
# 현재 집합의 단어와 맵핑된 고유한 정수 출력
print(TEXT.vocab.stoi)
# >>>defaultdict(<bound method Vocab._default_unk_index of <torchtext.legacy.vocab.Vocab object at 0x7f119a15e3d0>>, {'<unk>': 0, '<pad>': 1, 'the': 2, 'a': 3, 'and': 4, 'of': 5, 'to': 6, 'is': 7, 'in': 8, 'i': 9, 'this': 10, 'that': 11, 'it': 12, '/><br': 13, 'was': 14, 'as': 15, 'for': 16, 'with': 17, 'but': 18, 'on': 19, 'movie': 20, 'his': 21, 'are': 22, 'not': 23, 'film': 24, 'you': 25,...<생략>
# 임베딩 벡터의 개수와 각 벡터의 차원 확인
print('임베딩 벡터의 개수와 차원 : {} '.format(TEXT.vocab.vectors.shape))
# >>> 임베딩 벡터의 개수와 차원 : torch.Size([10002, 25])
# <unk>의 임베딩 벡터값 확인
print(TEXT.vocab.vectors[0]) # <unk>의 임베딩 벡터값
# >>> tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
# 0.])
# <pad>의 임베딩 벡터값 확인
print(TEXT.vocab.vectors[1]) # <pad>의 임베딩 벡터값
# >>>
# tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
# 0.])
# 'this'의 임베딩 벡터값 확인
print(TEXT.vocab.vectors[10]) # this의 임베딩 벡터값
# >>>
# tensor([-0.1789, 0.3841, 0.0730, -0.3236, -0.0924, -0.4077, 2.1000, -0.1136,
# -0.5878, -0.1703, -0.6433, 0.7239, -5.7839, -0.1041, 0.5215, -0.1131,
# 0.5955, -0.4759, -0.4551, 0.0844, -0.4582, -0.1673, 0.5459, 0.0355,
# -0.1607])
# 'self-indulgent'의 임베딩 벡터값 확인
# 사전 훈련된 임베딩 벡터에는 해당 단어가 존재하지 않기 때문에 0으로 초기화
print(TEXT.vocab.vectors[9999]) # seeing의 임베딩 벡터값
# >>>
# tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
# 0.])
# 이 임베딩 벡터들이 저장되어져 있는 TEXT.vocab.vectors를 nn.Embedding()의 초기화 입력으로 사용
embedding_layer = nn.Embedding.from_pretrained(TEXT.vocab.vectors, freeze=False)
embedding_layer(torch.LongTensor([10])) # 단어 this의 임베딩 벡터값
네이버 영화 리뷰 Word2Vec 생성 후 테스트
- 데이터 로드 후 전처리(결측값 제거 및 한글, 띄어쓰기 외 문자 제거)
!pip install konlpy # 형태소 분석기 설치# 도구 임포트
import pandas as pd
import matplotlib.pyplot as plt
import urllib.request
from gensim.models.word2vec import Word2Vec
from konlpy.tag import Okt
from tqdm import tqdm # 현재 for문이 얼마나 실행되었는지를 알려주는 라이브러리# 네이버 영화 리뷰 데이터 다운로드
urllib.request.urlretrieve("https://raw.githubusercontent.com/e9t/nsmc/master/ratings.txt", filename="ratings.txt")# 리뷰 데이터를 데이터프레임으로 로드
train_data = pd.read_table('ratings.txt')# 결측값 유무 확인
# NULL 값 존재 유무
print(train_data.isnull().values.any())# 결측값이 존재하는 행 제거
train_data = train_data.dropna(how = 'any') # Null 값이 존재하는 행 제거# 정규 표현식을 통한 한글 외 문자 제거
train_data['document'] = train_data['document'].str.replace("[^ㄱ-ㅎㅏ-ㅣ가-힣 ]","")# 학습 시에 사용하지 않는 불용어 제거, 형태소 분석기를 사용해 각 문장에 대해 토큰화 수행
# 불용어 정의
stopwords = ['의','가','이','은','들','는','좀','잘','걍','과','도','를','으로','자','에','와','한','하다']
# 형태소 분석기 OKT를 사용한 토큰화 작업 (다소 시간 소요)
okt = Okt()
tokenized_data = []
for sentence in tqdm(train_data['document'][:5000]): # 5000개만 사용
tokenized_sentence = okt.morphs(sentence, stem=True) # 토큰화
stopwords_removed_sentence = [word for word in tokenized_sentence if not word in stopwords] # 불용어 제거
tokenized_data.append(stopwords_removed_sentence)# 각리뷰의 길이 분포 확인
# 리뷰 길이 분포 확인
print('리뷰의 최대 길이 :',max(len(review) for review in tokenized_data))
print('리뷰의 평균 길이 :',sum(map(len, tokenized_data))/len(tokenized_data))
plt.hist([len(review) for review in tokenized_data], bins=50)
plt.xlabel('length of samples')
plt.ylabel('number of samples')
plt.show()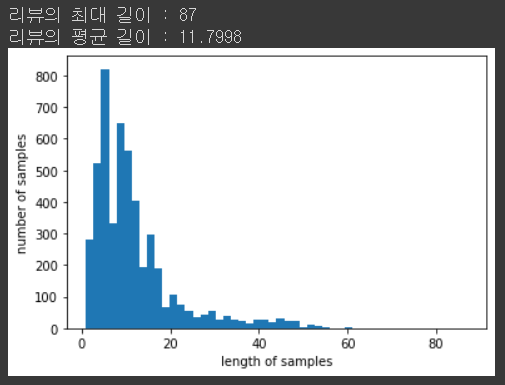
- Word2Vec 으로 토큰화 된 네이버 영화 리뷰 데이터 벡터화(학습)
# 모델 정의
from gensim.models import Word2Vec
model = Word2Vec(sentences = tokenized_data, size = 100, window = 5, min_count = 5, workers = 4, sg = 0)Word2Vec 의 하이퍼파라미터 값
|
# Word2Vec 임베딩 행렬 크기 확인
model.wv.vectors.shape # 총 1592개의 단어 존재 및 각 단어는 100차원으로 구성
# '최민식'과 유사한 단어 추출
print(model.wv.most_similar("최민식"))
AI-HUB 일반 상식 데이터 Word2Vec 생성 후 테스트
데이터: ko_wiki_v1_squad.json
1. 형태소 분석기 설치
!pip install konlpy
2. 도구 임포트
# 도구 임포트
import pandas as pd
import matplotlib.pyplot as plt
import urllib.request
from gensim.models.word2vec import Word2Vec
from konlpy.tag import Okt
from tqdm import tqdm # 현재 for문이 얼마나 실행되었는지를 알려주는 라이브러리
import json
3. json 내용 확인
# 코렙에 구글 드라이브 권한 부여 #01
from google.colab import drive
drive.mount('/content/gdrive')
# pprint를 통한 데이터 확인
from pprint import pprint
with open('/content/gdrive/My Drive/Colab Notebooks/ko_wiki_v1_squad.json') as data_file:
local = json.load(data_file)
pprint(local) # 출력 생략
4. json 데이터의 첫번째 문장 확인
# 불러온 json 데이터의 첫번째 문장 확인
local['data'][0]['paragraphs'][0]['context']
5. json 데이터의 context를 train_data에 담음
train_data = []
for i in tqdm(local['data']):
context = i['paragraphs'][0]['context']
train_data.append(context)
6. train_data 1000개를 데이터프레임에 담음
pd_data = pd.DataFrame()
pd_data['context'] = train_data[:1000]
7. 전처리 수행
# 정규 표현식을 통해 한글이 아닌경우 제거하는 전처리 수행
# 정규 표현식을 통한 한글 외 문자 제거
pd_data['context'] = pd_data['context'].str.replace("[^ㄱ-ㅎㅏ-ㅣ가-힣 ]","")
# 학습 시에 사용하지 않는 불용어 제거, 형태소 분석기를 사용해 각 문장에 대해 토큰화 수행
# 불용어 정의
stopwords = ['의','가','이','은','들','는','좀','잘','걍','과','도','를','으로','자','에','와','한','하다']
# 형태소 분석기 OKT를 사용한 토큰화 작업 (다소 시간 소요)
okt = Okt()
tokenized_data = []
for sentence in tqdm(pd_data['context']):
tokenized_sentence = okt.morphs(sentence, stem=True) # 토큰화
stopwords_removed_sentence = [word for word in tokenized_sentence if not word in stopwords] # 불용어 제거
tokenized_data.append(stopwords_removed_sentence)
8. 모델 정의 및 저장
# 모델 정의
from gensim.models import Word2Vec
model = Word2Vec(sentences = tokenized_data, size = 100, window = 5, min_count = 5, workers = 4, sg = 0)
# 모델 저장
from gensim.models import KeyedVectors
model.wv.save_word2vec_format('aihub_wiki_w2v')
# 코렙에 모델 저장
# torch.savq 메소스 사용
import torch
model_save_name = 'aihub_wiki_w2v'
path = F"/content/gdrive/My Drive/Colab Notebooks/{model_save_name}"
torch.save(model, path)
9. Word2Vec 임베딩 행렬 크기 확인
# Word2Vec 임베딩 행렬 크기 확인
model.wv.vectors.shape # 총 3940개의 단어 존재 및 각 단어는 100차원으로 구성
10. 테스트
# '우승'과 유사한 단어 추출
print(model.wv.most_similar("우승"))
11. 결과 파악
- 데이터셋의 문장의 도메인이 일관성이 없음. 크게 유의미한 결과를 얻기 힘듬
- 데이터가 중요
참고:
https://wikidocs.net/book/2788
PyTorch로 시작하는 딥 러닝 입문
이 책은 딥 러닝 프레임워크 PyTorch를 사용하여 딥 러닝에 입문하는 것을 목표로 합니다. 이 책은 2019년에 작성된 책으로 비영리적 목적으로 작성되어 출판 ...
wikidocs.net
'AI > PyTorch' 카테고리의 다른 글
| PyTorch #다대다 RNN (0) | 2022.04.06 |
|---|---|
| PyTorch #순환 신경망(RNN) (0) | 2022.04.06 |
| PyTorch #자연어 데이터 전처리 (0) | 2022.04.04 |
| PyTorch #합성곱 신경망(CNN) (0) | 2022.04.01 |
| PyTorch #인공 신경망(ANN) (0) | 2022.03.30 |



