합성곱 신경망(Convolutional Neural Network)
- 이미지 처리에 탁월한 성능
- 크게 합성곱층(Convolution layer)와 풀링층(Pooling layer)로 구성
- 이미지의 공간적인 구조 정보를 보존하면서 학습한다
01. 합성곱과 풀링
채널(Channel)
- 이미지는 높이, 너비, 채널(RGB 성분)의 3차원 텐서
- 가로 세로 28 픽셀의 흑백 이미지는 28 x 28 x 1 의 크기를 가지는 3차원 텐서
- 가로 세로 28 픽셀의 컬러 이미지는 28 x 28 x 3 의 크기를 가지는 3차원 텐서
합성곱 연산(Convolution operation)
- 합성곱층은 합성곱 연산을 통해 이미지의 특징을 추출하는 역할
- 커널(kernel) or 필터(filter)라는 n x m 크기로 높이 x 너비 크기의 이미지를 처음부터 끝까지 훑으면서 n x m 크기의 겹쳐지는 부분의 각 이미지와 커널의 원소의 값을 곱해서 모두 더한 값을 출력으로 하는 것. 이미지의 왼쪽 위부터 가장 오른쪽 아래까지 순차적으로 진행
- 커널은 일반적으로 3 x 3 또는 5 x 5를 사용
- 특성맵(feature map)은 입력으로부터 커널을 사용해 합성곱 연산을 통해 나온 결과를 말함
- 스트라이드(stride) : 커널의 이동범위, 사용자가 정의할 수 있음
예) 3x3 크기의 커널로 5x5 이미지 행렬에 합성곱 연산을 수행하는 과정

출력층의 6이 나온 과정 : (1×1) + (2×0) + (3×1) + (2×1) + (1×0) + (0×1) + (3×0) + (0×1) + (1×0) = 6
예) 스트라이드가 2인 경우(커널이 두칸까지 이동) 5x5 이미지에 합성곱 연산을 수행하는 3x3 커널의 움직임

패딩(Padding)
- 합성곱 연산의 결과로 얻은 특성 맵은 입력보다 크기가 작아지는 특징이 있음
- 합성곱 연산 이후에도 특성 맵의 크기가 입력의 크기와 동일하게 유지되도록 하려면 패딩을 사용
- 패딩은 합성곱 연산 전의 입력 가장자리에 지정된 개수의 폭만큼 행과 열을 추가해주는 것을 말함, 주로 0으로 채우는 제로 패딩을 사용 * 간단히 이미지 입력층 둘레에 0으로 된 테두리를 추가해 주는 것
합성곱 신경망의 가중치
- 합성곱 신경망은 다층 퍼셉트론보다 훨씬 적은 수의 가중치를 사용하며, 공간적 구조 정보를 보존하는 특징을 가짐
- 합성곱 연산을 통해 얻은 특성 맵은 비선형성 추가를 위해 렐루 함수나 렐루 함수의 변형들이 주로 사용됨
- 합성곱 연산을 통해 특성맵을 얻고, 활성화 함수를 지나는 연산을 하는 합성곱 신경망의 은닉층을 합성곱 층(convolution layer)이라고 함
합성곱 신경망의 편향
- 합성곱 신경마에도 편향(bias)를 추가할 수 있음
- 편향을 사용한다면 커널을 적용한 뒤에 더해짐
- 편향은 하나의 값만 존재하며, 커널이 적용된 결과의 모든 원소에 더해짐

특성 맵의 크기 계산
- 5x5 크기의 이미지에 3x3 커널을 사용하고 스트라이드 1로 합성곱 연산을 했을 때

- 5x5 크기의 이미지에 3x3 커널을 사용하고 스트라이드 2로 합성곱 연산을 했을 때

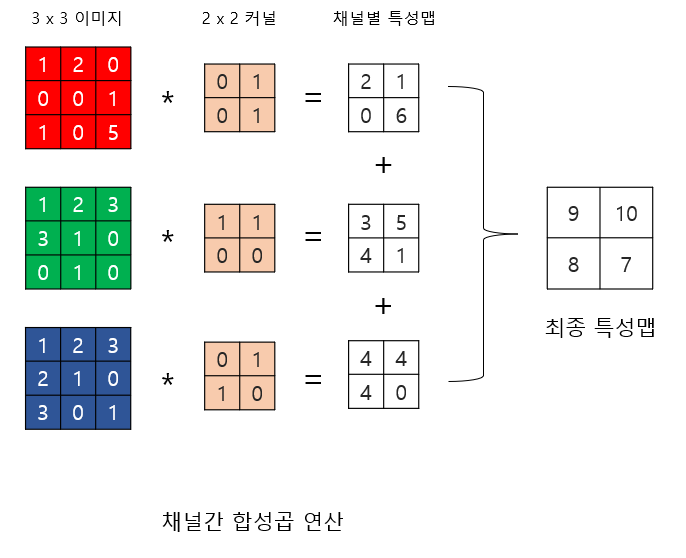
다수의 채널을 가질 경우의 합성곱 연산(3차원 텐서의 경우)
- 다수의 채널을 가진 입력 데이터를 가지고 합성곱 연산을 수행할 경우 커널의 채널 수도 입력의 채널 수 만큼 존재해야 함, 즉 입력 데이터의 채널 수와 커널의 채널 수는 같아야 함
- 채널 수가 같으므로 합성곱 연산을 채널마다 수행
- 그 결과를 모두 더해 최종 특성맵을 얻음
예시)
높이3, 너비3, 채널3의 입력이 높이2, 너비2, 채널3의 커널과 합성곱 연산을 하여 높이2 너비2 채널1의 특성맵을 가짐
* 커널의 파라미터
- 커널의 파라미터를 사람의 직관이나 반복적인 실험을 통해 조정해 적용함으로 이미지 분류 정확도를 최대화하는 필터를 찾아낼 수 있다. (뭐 이미지는 천차만별이니, 커널 파라미터도 조정이 필요하다는 얘기)
- 아래 사진은 원래 존재하던 이미지 필터의 파라미터, CNN은 이것을 참고해 인공신경망에 적용한 것

풀링(Pooling)
- 합성곱 층(합성곱 연산 + 활성화 함수) 다음에는 풀링층을 추가하는 것이 일반적
- 풀링 층에서는 특성 맵을 다운샘플링하여 특성 맵의 크기를 줄이는 풀링 연산이 이루어짐
- 풀링 연산에는 일반적으로 최대 풀링(max pooling)과 평균 풀링(average pooling)이 사용됨
- 풀링층을 추가하는 이유: 출력 데이터의 크기를 줄이거나, 특정 데이터를 강조하는 용도로 사용
02. CNN 으로 MNIST 분류
모델의 이해
1. 표기 방법 정의
합성곱 층 = 합성곱(nn.Conv2d) + 활성화 함수(nn.ReLU) + 맥스풀링(nn.MaxPoold2d)
2. 모델의 아키텍처
1번 레이어 : 합성곱층(Convolutional layer)
- 합성곱(in_channel = 1, out_channel = 32, kernel_size=3, stride=1, padding=1) + 활성화 함수 ReLU
- 맥스풀링(kernel_size=2, stride=2))
2번 레이어 : 합성곱층(Convolutional layer)
- 합성곱(in_channel = 32, out_channel = 64, kernel_size=3, stride=1, padding=1) + 활성화 함수 ReLU
- 맥스풀링(kernel_size=2, stride=2))
3번 레이어 : 전결합층(Fully-Connected layer)
- 특성맵을 펼친다. # batch_size × 7 × 7 × 64 → batch_size × 3136
- 전결합층(뉴런 10개) + 활성화 함수 Softmax
모델 구현
1. 필요한 도구 임포트 및 입력 정의
# 도구 임포트, 입력 정의
import torch
import torch.nn as nn
# 텐서 생성 1x1x28x28
# 배치 크기 × 채널 × 높이(height) × 너비(widht)의 크기의 텐서를 선언
inputs = torch.Tensor(1, 1, 28, 28)
print('텐서의 크기 : {}'.format(inputs.shape))
2. 합성곱 층과 풀링 선언
# 첫 번째 합성곱 층, 1채널 입력, 32채널 출력, 커널 사이즈 3, 패딩 1
conv1 = nn.Conv2d(1, 32, 3, padding=1)
print(conv1)
# 두 번째 합성곱 층, 32채널 입력, 64채널 출력, 커널 사이즈 3, 패딩 1
conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
print(conv2)
# 맥스 풀링 구현, 정수 하나를 인자로 넣으면 커널 사이즈와 스트라이드가 둘 다 해당값으로 지정됨
pool = nn.MaxPool2d(2)
print(pool)
3. 구현한 층들을 연결하여 모델 생성
# 우선 입력을 첫 번째 합성곱층을 통과 시키고 통과시킨 후의 텐서 크기 확인
out = conv1(inputs)
print(out.shape) # 32채널의 28 x 28 사이즈의 텐서 확인
# 맥스 풀링을 통과 시킨 뒤의 텐서 크기 확인
out = pool(out)
print(out.shape) # 32채널의 14 x 14 사이즈의 텐서 확인
# 두 번째 합성곱층에 통과 시키고 텐서 크기 확인
out = conv2(out)
print(out.shape) # 64 채널의 14 x 14 사이즈의 텐서 확인
# 맥스 풀링을 통과 시킨 뒤의 텐서 크기 확인
out = pool(out)
print(out.shape) # 64 채널의 7 x 7 사이즈의 텐서 확인
# out의 첫번째 차원이 몇인지 출력
out.size(0)
# out의 두번째 차원이 몇인지 출력
out.size(1)
# out의 세번째 차원이 몇인지 출력
out.size(2)
# out의 네번째 차원이 몇인지 출력
out.size(3)
# .view()를 사용해 텐서를 펼치는 작업
# 첫번째 차원인 배치 차원은 그대로 두고 나머지는 펼쳐라
out = out.view(out.size(0), -1)
print(out.shape) # 배치 차원을 제외하고 모두 하나의 차원으로 통합
# 펼쳐진 텐서를 전결합층 통과, 출력층으로 10개의 뉴런을 배치해 10개 차원의 텐서로 변환
fc = nn.Linear(3136, 10) # input_dim = 3,136, output_dim = 10
out = fc(out)
print(out.shape)
3. CNN으로 MNIST 분류
# 도구 임포트
import torch
import torchvision.datasets as dsets
import torchvision.transforms as transforms
import torch.nn.init
# GPU 설정 및 랜덤 시드 설정
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# 랜덤 시드 고정
torch.manual_seed(777)
# GPU 사용 가능일 경우 랜덤 시드 고정
if device == 'cuda':
torch.cuda.manual_seed_all(777)
# 학습에 사용할 파라미터 설정
learning_rate = 0.001
training_epochs = 15
batch_size = 100
# 데이터로더를 사용해 MNIST 데이터셋 정의
mnist_train = dsets.MNIST(root='MNIST_data/', # 다운로드 경로 지정
train=True, # True를 지정하면 훈련 데이터로 다운로드
transform=transforms.ToTensor(), # 텐서로 변환
download=True)
mnist_test = dsets.MNIST(root='MNIST_data/', # 다운로드 경로 지정
train=False, # False를 지정하면 테스트 데이터로 다운로드
transform=transforms.ToTensor(), # 텐서로 변환
download=True)
# 데이터로더를 사용해 배치 크기 지정
data_loader = torch.utils.data.DataLoader(dataset=mnist_train,
batch_size=batch_size,
shuffle=True,
drop_last=True)
# 클래스로 모델 설계
class CNN(torch.nn.Module):
def __init__(self):
super(CNN, self).__init__()
# 첫번째층
# ImgIn shape=(?, 28, 28, 1)
# Conv -> (?, 28, 28, 32)
# Pool -> (?, 14, 14, 32)
self.layer1 = torch.nn.Sequential(
torch.nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2))
# 두번째층
# ImgIn shape=(?, 14, 14, 32)
# Conv ->(?, 14, 14, 64)
# Pool ->(?, 7, 7, 64)
self.layer2 = torch.nn.Sequential(
torch.nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2))
# 전결합층 7x7x64 inputs -> 10 outputs
self.fc = torch.nn.Linear(7 * 7 * 64, 10, bias=True)
# 전결합층 한정으로 가중치 초기화
torch.nn.init.xavier_uniform_(self.fc.weight)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.view(out.size(0), -1) # 전결합층을 위해서 Flatten
out = self.fc(out)
return out
# CNN 모델 정의
model = CNN().to(device)
# 비용 함수와 옵티마이저 정의
criterion = torch.nn.CrossEntropyLoss().to(device) # 비용 함수에 소프트맥스 함수 포함되어져 있음.
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# 총 배치 수 출력
total_batch = len(data_loader)
print('총 배치의 수 : {}'.format(total_batch)) # 총배치수는 600, 배치사이즈는 100이므로 훈련 데이터는 총 60,000개
# 모델 훈련
for epoch in range(training_epochs):
avg_cost = 0
for X, Y in data_loader: # 미니 배치 단위로 꺼내온다. X는 미니 배치, Y는 레이블.
# image is already size of (28x28), no reshape
# label is not one-hot encoded
X = X.to(device)
Y = Y.to(device)
optimizer.zero_grad()
hypothesis = model(X)
cost = criterion(hypothesis, Y)
cost.backward()
optimizer.step()
avg_cost += cost / total_batch
print('[Epoch: {:>4}] cost = {:>.9}'.format(epoch + 1, avg_cost))
# 테스트
# 학습을 진행하지 않을 것이므로 torch.no_grad()
with torch.no_grad():
X_test = mnist_test.test_data.view(len(mnist_test), 1, 28, 28).float().to(device)
Y_test = mnist_test.test_labels.to(device)
prediction = model(X_test)
correct_prediction = torch.argmax(prediction, 1) == Y_test
accuracy = correct_prediction.float().mean()
print('Accuracy:', accuracy.item())
4. 깊은 CNN으로 MNIST 분류(합성곱층 하나와 전결합층 하나를 추가)
1번 레이어 : 합성곱층(Convolutional layer)
- 합성곱(in_channel = 1, out_channel = 32, kernel_size=3, stride=1, padding=1) + 활성화 함수 ReLU
- 맥스풀링(kernel_size=2, stride=2))
2번 레이어 : 합성곱층(Convolutional layer)
- 합성곱(in_channel = 32, out_channel = 64, kernel_size=3, stride=1, padding=1) + 활성화 함수 ReLU
- 맥스풀링(kernel_size=2, stride=2))
3번 레이어 : 합성곱층(Convolutional layer)
- 합성곱(in_channel = 64, out_channel = 128, kernel_size=3, stride=1, padding=1) + 활성화 함수 ReLU
- 맥스풀링(kernel_size=2, stride=2, padding=1))
4번 레이어 : 전결합층(Fully-Connected layer)
- 특성맵을 펼친다. # batch_size × 4 × 4 × 128 → batch_size × 2048
- 전결합층(뉴런 625개) + 활성화 함수 ReLU
5번 레이어 : 전결합층(Fully-Connected layer)
- 전결합층(뉴런 10개) + 활성화 함수 Softmax
# 도구 임포트
import torch
import torchvision.datasets as dsets
import torchvision.transforms as transforms
import torch.nn.init
# GPU 설정
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# 랜덤 시드 고정
torch.manual_seed(777)
# GPU 사용 가능일 경우 랜덤 시드 고정
if device == 'cuda':
torch.cuda.manual_seed_all(777)
# 학습 파라미터 설정
learning_rate = 0.001
training_epochs = 15
batch_size = 100
# 데이터 셋 정의
mnist_train = dsets.MNIST(root='MNIST_data/', # 다운로드 경로 지정
train=True, # True를 지정하면 훈련 데이터로 다운로드
transform=transforms.ToTensor(), # 텐서로 변환
download=True)
mnist_test = dsets.MNIST(root='MNIST_data/', # 다운로드 경로 지정
train=False, # False를 지정하면 테스트 데이터로 다운로드
transform=transforms.ToTensor(), # 텐서로 변환
download=True)
# 배치 크기 지정
data_loader = torch.utils.data.DataLoader(dataset=mnist_train,
batch_size=batch_size,
shuffle=True,
drop_last=True)
# 클래스로 모델 생성
class CNN(torch.nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.keep_prob = 0.5
# L1 ImgIn shape=(?, 28, 28, 1)
# Conv -> (?, 28, 28, 32)
# Pool -> (?, 14, 14, 32)
self.layer1 = torch.nn.Sequential(
torch.nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2))
# L2 ImgIn shape=(?, 14, 14, 32)
# Conv ->(?, 14, 14, 64)
# Pool ->(?, 7, 7, 64)
self.layer2 = torch.nn.Sequential(
torch.nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2))
# L3 ImgIn shape=(?, 7, 7, 64)
# Conv ->(?, 7, 7, 128)
# Pool ->(?, 4, 4, 128)
self.layer3 = torch.nn.Sequential(
torch.nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),
torch.nn.ReLU(),
torch.nn.MaxPool2d(kernel_size=2, stride=2, padding=1))
# L4 FC 4x4x128 inputs -> 625 outputs
self.fc1 = torch.nn.Linear(4 * 4 * 128, 625, bias=True)
torch.nn.init.xavier_uniform_(self.fc1.weight)
self.layer4 = torch.nn.Sequential(
self.fc1,
torch.nn.ReLU(),
torch.nn.Dropout(p=1 - self.keep_prob))
# L5 Final FC 625 inputs -> 10 outputs
self.fc2 = torch.nn.Linear(625, 10, bias=True)
torch.nn.init.xavier_uniform_(self.fc2.weight)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = self.layer3(out)
out = out.view(out.size(0), -1) # Flatten them for FC
out = self.layer4(out)
out = self.fc2(out)
return out
# 모델 정의
model = CNN().to(device)
# 비용 함수 및 옵피마이저 정의
criterion = torch.nn.CrossEntropyLoss().to(device) # 비용 함수에 소프트맥스 함수 포함되어져 있음.
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# 배치 수 조정
total_batch = len(data_loader)
print('총 배치의 수 : {}'.format(total_batch))
# 모델 훈련
for epoch in range(training_epochs):
avg_cost = 0
for X, Y in data_loader: # 미니 배치 단위로 꺼내온다. X는 미니 배치, Y느 ㄴ레이블.
# image is already size of (28x28), no reshape
# label is not one-hot encoded
X = X.to(device)
Y = Y.to(device)
optimizer.zero_grad()
hypothesis = model(X)
cost = criterion(hypothesis, Y)
cost.backward()
optimizer.step()
avg_cost += cost / total_batch
print('[Epoch: {:>4}] cost = {:>.9}'.format(epoch + 1, avg_cost))
# 모델 테스트
# 학습을 진행하지 않을 것이므로 torch.no_grad()
with torch.no_grad():
X_test = mnist_test.test_data.view(len(mnist_test), 1, 28, 28).float().to(device)
Y_test = mnist_test.test_labels.to(device)
prediction = model(X_test)
correct_prediction = torch.argmax(prediction, 1) == Y_test
accuracy = correct_prediction.float().mean()
print('Accuracy:', accuracy.item())
아래는 CNN으로 테스트한 결과
합성곱 층과 전결합 층을 추가해 학습시켰지만 정확도는 크게 향상되지 않음, 참고한 예제에선 오히려 떨어지는 경우도 발생. 무조건 층을 깊게 쌓는 것보다 효율을 생각하는 것이 중요
참고:
https://wikidocs.net/book/2788
PyTorch로 시작하는 딥 러닝 입문
이 책은 딥 러닝 프레임워크 PyTorch를 사용하여 딥 러닝에 입문하는 것을 목표로 합니다. 이 책은 2019년에 작성된 책으로 비영리적 목적으로 작성되어 출판 ...
wikidocs.net
'AI > PyTorch' 카테고리의 다른 글
| PyTorch #원-핫 인코딩 #워드 임베딩 (0) | 2022.04.05 |
|---|---|
| PyTorch #자연어 데이터 전처리 (0) | 2022.04.04 |
| PyTorch #인공 신경망(ANN) (0) | 2022.03.30 |
| PyTorch #소프트맥스 회귀(Softmax Regression) (0) | 2022.03.24 |
| PyTorch #로지스틱 회귀(Logistic Regression) (0) | 2022.03.23 |



