다대다 RNN
- 모든 시점의 입력에 대해서 모든 시점에 출력을 함
- 대표적으로 품사 태깅, 개체명 인식 등에 사용
1. 문자 단위 RNN(Char RNN)
- RNN의 입출력 단위가 단어 레벨이 아닌 문자 레벨
- 도구 임포트
# 도구 임포트
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
- 훈련 데이터 전처리
# sputnik!!를 입력 받으면 satellite 를 출력하는 RNN 구현
# 1. 입력 데이터와 레이블 데이터에 대해 문자 집합(vocabulary) 생성, 이때 문자 집합은 중복을 제거한 문자들의 집합
input_str = 'sputnik!!'
label_str = 'satellite'
char_vocab = sorted(list(set(input_str+label_str))) # 중복을 제거한 문자
vocab_size = len(char_vocab)
print ('문자 집합의 크기 : {}'.format(vocab_size))
- 하이퍼파라미터 정의
# 하이퍼파라미터 정의, 입력은 원-핫 벡터를 사용할 것이므로 입력의 크기는 문자 집합의 크기(10)여야만 함
input_size = vocab_size # 입력의 크기는 문자 집합의 크기
hidden_size = 11
output_size = 11
learning_rate = 0.1
- 입력의 크기는 문자 집합의 크기, 입력을 원-핫 벡터로 사용하기 위해 문자 집합에 고유한 정수 부여
# 문자 집합에 고유한 정수 부여
char_to_index = dict((c, i) for i, c in enumerate(char_vocab)) # 문자에 고유한 정수 인덱스 부여
print(char_to_index)
- 원-핫 벡터를 문자 집합으로 보기 위한 변수 생성
# 예측 결과를 다시 문자 시퀀스로 보기 위해, 정수로부터 문자를 얻을 수 있는 index_to_char 생성
index_to_char={}
for key, value in char_to_index.items():
index_to_char[value] = key
print(index_to_char)
- 입력 데이터와 레이블 데이터를 문자 집합의 정수로 맵핑
# 입력 데이터와 레이블 데이터를 각 문자들의 정수로 맵핑
x_data = [char_to_index[c] for c in input_str]
y_data = [char_to_index[c] for c in label_str]
print(x_data)
print(y_data)
- 파이토치 용으로 2차원 텐서를 3차원으로 변경
# 파이토치의 nn.RNN()은 기본으로 3차원 텐서를 입력받기 때문에 배치 차원 추가.
# 배치 차원 추가
# 텐서 연산인 unsqueeze(0)를 통해 해결할 수도 있었음.
x_data = [x_data]
y_data = [y_data]
print(x_data)
print(y_data)
- 입력 시퀀스의 각 문자(sputnik!!)을 원-핫 벡터로 변경
# 입력 시퀀스의 각 문자들을 원-핫 벡터로 변경
x_one_hot = [np.eye(vocab_size)[x] for x in x_data]
print(x_one_hot)
# 입력 데이터와 레이블 데이터를 텐서로 변경
X = torch.FloatTensor(x_one_hot)
Y = torch.LongTensor(y_data)# 각 텐서의 크기 확인
print('훈련 데이터의 크기 : {}'.format(X.shape))
print('레이블의 크기 : {}'.format(Y.shape))
- 모델 구현
# 모델 구현, fc는 완전 연결층(fully-connected layer)를 의미하며 출력층으로 사용
class Net(torch.nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(Net, self).__init__()
self.rnn = torch.nn.RNN(input_size, hidden_size, batch_first=True) # RNN 셀 구현
self.fc = torch.nn.Linear(hidden_size, output_size, bias=True) # 출력층 구현
def forward(self, x): # 구현한 RNN 셀과 출력층을 연결
x, _status = self.rnn(x)
x = self.fc(x)
return x# 정의한 모델을 net에 저장
net = Net(input_size, hidden_size, output_size)# 모델에 입력을 넣어 출력 크기 확인
outputs = net(X)
print(outputs.shape) # 3차원 텐서, [배치차원, 시점, 출력의 크기]
# 정확도 측정을 위해 모두 펼쳐서 계산, view를 사용해 배치 차원과 시점 차원을 하나로 만듬
print(outputs.view(-1, input_size).shape) # 2차원 텐서로 변환
# 레이블 데이터 크기 확인
print(Y.shape)
print(Y.view(-1).shape)
- 옵티마이저 및 손실 함수 정의
# 옵티마이저 및 손실함수 정의
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), learning_rate)
- 모델 학습
# 학습, 에포크 50번
for i in range(50):
optimizer.zero_grad()
outputs = net(X)
loss = criterion(outputs.view(-1, input_size), Y.view(-1)) # view를 하는 이유는 Batch 차원 제거를 위해
loss.backward() # 기울기 계산
optimizer.step() # 아까 optimizer 선언 시 넣어둔 파라미터 업데이트
# 아래 세 줄은 모델이 실제 어떻게 예측했는지를 확인하기 위한 코드.
result = outputs.data.numpy().argmax(axis=2) # 최종 예측값인 각 time-step 별 5차원 벡터에 대해서 가장 높은 값의 인덱스를 선택
result_str = ''.join([index_to_char[c] for c in np.squeeze(result)])
print(i, "loss: ", loss.item(), "prediction: ", result, "true Y: ", y_data, "prediction str: ", result_str)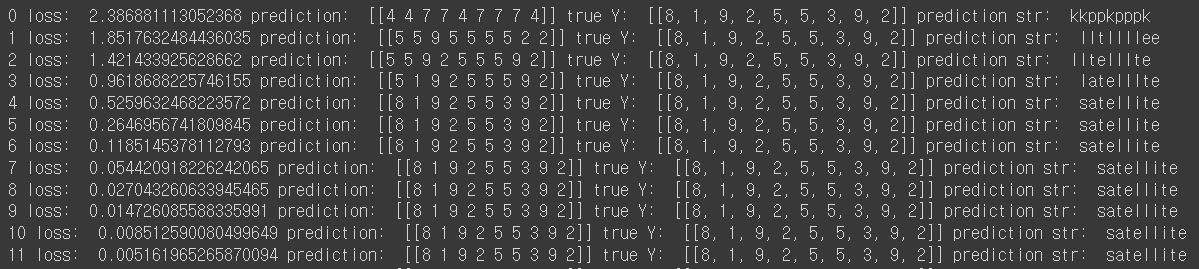

2. 더 많은 문자 단위 RNN(Char RNN)
# 도구 임포트
import torch
import torch.nn as nn
import torch.optim as optim
# 사용할 문장
sentence = ("Don't dwell on the past "
"Believe in yourself "
"Follow your heart")
# 문자 집합 생성 및 각 문자에 고유한 정수 부여
char_set = list(set(sentence)) # 중복을 제거한 문자 집합 생성
char_dic = {c: i for i, c in enumerate(char_set)} # 각 문자에 정수 인코딩
# 문자 집합의 크기
dic_size = len(char_dic)
# 하이퍼파라미터 설정, hidden_size는 입력의 크기와 다른 값을 줘도 무방, swquence_length는 샘플을 10개 단위로 끊기 위해
hidden_size = dic_size
sequence_length = 10 # 임의 숫자 지정
learning_rate = 0.1
# 10단위로 샘플들을 잘라서 데이터 생성
x_data = []
y_data = []
for i in range(0, len(sentence) - sequence_length):
x_str = sentence[i:i + sequence_length]
y_str = sentence[i + 1: i + sequence_length + 1]
print(i, x_str, '->', y_str)
x_data.append([char_dic[c] for c in x_str]) # x str to index
y_data.append([char_dic[c] for c in y_str]) # y str to index

# 입력 시퀀스에 대해 원-핫 인코딩 수행 및 입력 데이터와 레이블 데이터를 텐서로 변환
x_one_hot = [np.eye(dic_size)[x] for x in x_data] # x 데이터는 원-핫 인코딩
X = torch.FloatTensor(x_one_hot)
Y = torch.LongTensor(y_data)
# 모델 구현
class Net(torch.nn.Module):
def __init__(self, input_dim, hidden_dim, layers): # 현재 hidden_size는 dic_size와 같음.
super(Net, self).__init__()
self.rnn = torch.nn.RNN(input_dim, hidden_dim, num_layers=layers, batch_first=True)
self.fc = torch.nn.Linear(hidden_dim, hidden_dim, bias=True)
def forward(self, x):
x, _status = self.rnn(x)
x = self.fc(x)
return x
# 모델 객체 생성
net = Net(dic_size, hidden_size, 2) # 이번에는 층을 두 개
# 비용함수, 옵티마이저 선언
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), learning_rate)
# 모델 훈련
for i in range(50):
optimizer.zero_grad()
outputs = net(X) # (170, 10, 25) 크기를 가진 텐서를 매 에포크마다 모델의 입력으로 사용
loss = criterion(outputs.view(-1, dic_size), Y.view(-1))
loss.backward()
optimizer.step()
# results의 텐서 크기는 (170, 10)
results = outputs.argmax(dim=2)
predict_str = ""
for j, result in enumerate(results):
if j == 0: # 처음에는 예측 결과를 전부 가져오지만
predict_str += ''.join([char_set[t] for t in result])
else: # 그 다음에는 마지막 글자만 반복 추가
predict_str += char_set[result[-1]]
print(predict_str)
3. 단어 단위 RNN
# 도구 임포트
import torch
import torch.nn as nn
import torch.optim as optim
sentence = "기운센 천하장사! 무쇠로 만든 사람 인조인간 로보트".split()
# 단어집합 생성
vocab = list(set(sentence))
# 고유한 정수 인덱스 부여 및 단어를 의미하는 UNK 토큰 추가
word2index = {tkn: i for i, tkn in enumerate(vocab, 1)} # 단어에 고유한 정수 부여
word2index['<unk>']=0
# 예측 단계에서 예측한 문장을 확인하기 위한 idx2word 생성
# 수치화된 데이터를 단어로 바꾸기 위한 사전
index2word = {v: k for k, v in word2index.items()}
# 각 단어를 정수 인코딩 및, 입력 데이터와 레이블 데이터를 만드는 build_data 함수 생성
def build_data(sentence, word2index):
encoded = [word2index[token] for token in sentence] # 각 문자를 정수로 변환.
input_seq, label_seq = encoded[:-1], encoded[1:] # 입력 시퀀스와 레이블 시퀀스를 분리
input_seq = torch.LongTensor(input_seq).unsqueeze(0) # 배치 차원 추가
label_seq = torch.LongTensor(label_seq).unsqueeze(0) # 배치 차원 추가
return input_seq, label_seq
# 만들어진 함수로부터 입력데이터와 레이블 데이터 얻기
X, Y = build_data(sentence, word2index)
# 모델 구현
# 파이토치에서는 nn.Embedding()을 사용해 임베딩 층을 구현, 임베딩 층은 크게 두 가지 인자를 받는데 첫번째는 단어장의 크기, 두번째는 임베딩 벡터의 차원
class Net(nn.Module):
def __init__(self, vocab_size, input_size, hidden_size, batch_first=True):
super(Net, self).__init__()
self.embedding_layer = nn.Embedding(num_embeddings=vocab_size, # 워드 임베딩
embedding_dim=input_size)
self.rnn_layer = nn.RNN(input_size, hidden_size, # 입력 차원, 은닉 상태의 크기 정의
batch_first=batch_first)
self.linear = nn.Linear(hidden_size, vocab_size) # 출력은 원-핫 벡터의 크기를 가져야함. 또는 단어 집합의 크기만큼 가져야함.
def forward(self, x):
# 1. 임베딩 층
# 크기변화: (배치 크기, 시퀀스 길이) => (배치 크기, 시퀀스 길이, 임베딩 차원)
output = self.embedding_layer(x)
# 2. RNN 층
# 크기변화: (배치 크기, 시퀀스 길이, 임베딩 차원)
# => output (배치 크기, 시퀀스 길이, 은닉층 크기), hidden (1, 배치 크기, 은닉층 크기)
output, hidden = self.rnn_layer(output)
# 3. 최종 출력층
# 크기변화: (배치 크기, 시퀀스 길이, 은닉층 크기) => (배치 크기, 시퀀스 길이, 단어장 크기)
output = self.linear(output)
# 4. view를 통해서 배치 차원 제거
# 크기변화: (배치 크기, 시퀀스 길이, 단어장 크기) => (배치 크기*시퀀스 길이, 단어장 크기)
return output.view(-1, output.size(2))
# 하이퍼 파라미터 설정
vocab_size = len(word2index) # 단어장의 크기는 임베딩 층, 최종 출력층에 사용된다. <unk> 토큰을 크기에 포함한다.
input_size = 5 # 임베딩 된 차원의 크기 및 RNN 층 입력 차원의 크기
hidden_size = 20 # RNN의 은닉층 크기
# 모델 생성
model = Net(vocab_size, input_size, hidden_size, batch_first=True)
# 손실함수 정의
loss_function = nn.CrossEntropyLoss() # 소프트맥스 함수 포함이며 실제값은 원-핫 인코딩 안 해도 됨.
# 옵티마이저 정의
optimizer = optim.Adam(params=model.parameters())
# 모델 훈련 전, 예측이 제대로 되는지 예측된 정수 시퀀스를 넣어 시퀀스로 바꾸는 decode 함수 생성
# 수치화된 데이터를 단어로 전환하는 함수
decode = lambda y: [index2word.get(x) for x in y]
# 훈련 수행
for step in range(51):
# 경사 초기화
optimizer.zero_grad()
# 순방향 전파
output = model(X)
# 손실값 계산
loss = loss_function(output, Y.view(-1))
# 역방향 전파
loss.backward()
# 매개변수 업데이트
optimizer.step()
# 기록
if step % 5 == 0:
print("[{:02d}/51] {:.4f} ".format(step+1, loss))
pred = output.softmax(-1).argmax(-1).tolist()
print(" ".join(["기운센"] + decode(pred)))
print()


참고:
https://wikidocs.net/book/2788
PyTorch로 시작하는 딥 러닝 입문
이 책은 딥 러닝 프레임워크 PyTorch를 사용하여 딥 러닝에 입문하는 것을 목표로 합니다. 이 책은 2019년에 작성된 책으로 비영리적 목적으로 작성되어 출판 ...
wikidocs.net
반응형
'AI > PyTorch' 카테고리의 다른 글
| PyTorch #주피터 노트북 환경 세팅 (0) | 2022.04.08 |
|---|---|
| PyTorch #다대일 RNN (0) | 2022.04.07 |
| PyTorch #순환 신경망(RNN) (0) | 2022.04.06 |
| PyTorch #원-핫 인코딩 #워드 임베딩 (0) | 2022.04.05 |
| PyTorch #자연어 데이터 전처리 (0) | 2022.04.04 |



