선형 회귀(Linear Regression)
- 특성과 타깃 사이의 관계를 가장 잘 나타내는 선형 방정식을 찾음
- 특성이 하나면 직선 방정식이 됨
- 선형 회귀가 찾은 특성과 타깃 사이의 관계는 선형 방정식의 계수(기울기) 또는 가중치(기울기와 절편)에 저장됨
- 훈련 세트 범위 밖의 샘플을 예측
파이토치로 선형 회귀 구현
가중치(Weight)와 편향(bias) 초기화
- 선형회귀란 학습 데이터와 가장 잘 맞는 하나의 직선을 찾는 것
- 가장 잘 맞는 직선을 정의하는 것은 W와 b
- 선형 회귀의 목표는 가장 잘 맞는 직선을 정의하는 W와 b의 값을 찾는 것
- W와 b는 직선 방정식의 기울기와 y 절편에 해당
경사 하강법 구현
- SGD는 경사 하강법의 일종, Ir은 학습률(learning rate)를 의미
- 학습 대상인 W와 b가 SGD의 입력이 됨
SGD - 확률적 경사 하강법(Stochastic Gradient Descent)
- 점진적 학습의 대표적 알고리즘
- 훈련 세트에서 샘플 하나씩 꺼내(랜덤) 손실 함수의 경사를 따라 최적의 모델을 찾는 알고리즘
- 에포크(Epoch)는 전체 훈련 데이터가 학습에 한번 사용된 주기
optimizer.zero_grad() 가 필요한 이유
- 파이토치는 미분을 통해 얻은 기울기를 이전에 계산된 기울기 값에 누적시키는 특징이 있음
- 그렇기 때문에 optimizer.zero_grad()를 통해 미분값을 계속 0으로 초기화 시켜줘야 함
torch.manual_seed()를 하는 이유
- torch.manual_seed()를 사용한 프로그램의 결과는 다른 컴퓨터에서 실행시켜도 동일한 결과가 출력
- torch.manual_seed() 는 난수 발생 순서와 값을 동일하게 보장해준다는 특징이 있기 때문
데이터
| Hours (x) | Points (y) | |
| 1 | 2 | Training dataset |
| 2 | 4 | |
| 3 | 6 | |
| 4 | ? | Test dataset |
전체 코드
# 도구 임포트
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# 데이터
x_train = torch.FloatTensor([[1], [2], [3]])
y_train = torch.FloatTensor([[2], [4], [6]])
# 모델 초기화
W = torch.zeros(1, requires_grad=True)
b = torch.zeros(1, requires_grad=True)
# optimizer 설정
optimizer = optim.SGD([W, b], lr=0.01)
nb_epochs = 1999 # 원하는만큼 경사 하강법을 반복
for epoch in range(nb_epochs + 1):
# H(x) 계산
hypothesis = x_train * W + b
# cost 계산
cost = torch.mean((hypothesis - y_train) ** 2)
# cost로 H(x) 개선
optimizer.zero_grad()
cost.backward()
optimizer.step()
# 100번마다 로그 출력
if epoch % 100 == 0:
print('Epoch {:4d}/{} W: {:.3f}, b: {:.3f} Cost: {:.6f}'.format(
epoch, nb_epochs, W.item(), b.item(), cost.item()
))
* 최종 훈련 결과 기울기 W는 2에 가깝고, b는 0에 가까운 것을 확인
자동 미분(Autograd)
경사 하강법 코드를 보면 requires_grad = True, backward() 등이 나오는데 이는 파이토치에서 제공하고 있는 자동 미분(Autograd) 기능을 수행하는 것
- 자동 미분을 사용하면 미분 계산을 자동화하여 경사 하강법을 손쉽게 사용 가능
자동 미분 테스트
임의로 2w^{2} + 5 라는 식을 세우고, w에 대해 미분 수행
import torch
# 값이 2인 임의의 스칼라 텐서 w를 선언
# required_grad를 True로 설정, 이는 이 텐서에 대한 기울기를 저장하겠다는 의미, 이렇게 하면 w.grad에 w에 대한 미분값이 저장됨
w = torch.tensor(2.0, requires_grad=True)
# 수식 정의
y = w**2
z = 2*y + 5
# 수식을 w에 대해서 미분, .backward()를 호출해 해당 수식의 w에 대한 기울기를 계산
z.backward()
# w.grad를 출력하면 w가 속한 수식을 w로 미분한 값이 저장된 것을 확인
print('수식을 w로 미분한 값 : {}'.format(w.grad))
다중 선형 회귀(Multivariable Linear regression)
데이터
- 독립 변수 x의 개수가 3개, 3개의 퀴즈 점수로부터 최종 점수를 예측하는 모델 생성
| Quiz 1 (x1) | Quiz 2 (x2) | Quiz 3 (x3) | Final (y) |
| 73 | 60 | 75 | 152 |
| 93 | 88 | 93 | 185 |
| 89 | 91 | 80 | 180 |
| 96 | 98 | 100 | 196 |
| 73 | 66 | 70 | 142 |
파이토치로 구현
# 도구 임포트 및 랜덤 시드 고정
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
torch.manual_seed(1)
# 훈련 데이터 선언
x1_train = torch.FloatTensor([[73], [93], [89], [96], [73]])
x2_train = torch.FloatTensor([[80], [88], [91], [98], [66]])
x3_train = torch.FloatTensor([[75], [93], [90], [100], [70]])
y_train = torch.FloatTensor([[152], [185], [180], [196], [142]])
# 가중치 w와 편향 b 초기화
w1 = torch.zeros(1, requires_grad=True)
w2 = torch.zeros(1, requires_grad=True)
w3 = torch.zeros(1, requires_grad=True)
b = torch.zeros(1, requires_grad=True)
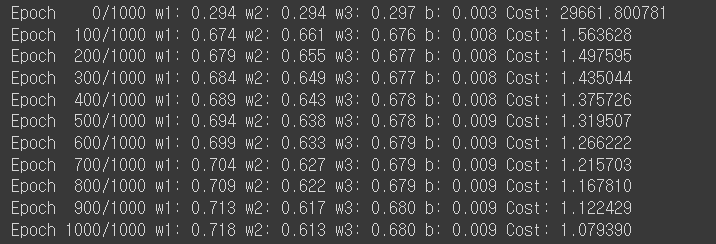
# 가설, 비용 함수, 옵티마이저를 선언한 후 경사 하강법을 1,000회 반복
# optimizer 설정
optimizer = optim.SGD([w1, w2, w3, b], lr=1e-5)
# 모델 훈련
nb_epochs = 1000
for epoch in range(nb_epochs + 1):
# H(x) 계산
hypothesis = x1_train * w1 + x2_train * w2 + x3_train * w3 + b
# cost 계산
cost = torch.mean((hypothesis - y_train) ** 2)
# cost로 H(x) 개선
optimizer.zero_grad()
cost.backward()
optimizer.step()
# 100번마다 로그 출력
if epoch % 100 == 0:
print('Epoch {:4d}/{} w1: {:.3f} w2: {:.3f} w3: {:.3f} b: {:.3f} Cost: {:.6f}'.format(
epoch, nb_epochs, w1.item(), w2.item(), w3.item(), b.item(), cost.item()
))
행렬 연산을 고려해 파이토치로 구현
# 도구 임포트 및 랜덤 시드 고정
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
torch.manual_seed(1)
# 벡터와 행렬 연산으로 바꾸기
# 행렬 곱셈 연산을 사용
x_train = torch.FloatTensor([[73, 80, 75],
[93, 88, 93],
[89, 91, 80],
[96, 98, 100],
[73, 66, 70]])
y_train = torch.FloatTensor([[152], [185], [180], [196], [142]])
# 모델 초기화
W = torch.zeros((3, 1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
# optimizer 설정
optimizer = optim.SGD([W, b], lr=1e-5)
nb_epochs = 20
for epoch in range(nb_epochs + 1):
# H(x) 계산
# 편향 b는 브로드 캐스팅되어 각 샘플에 더해집니다.
hypothesis = x_train.matmul(W) + b
# cost 계산
cost = torch.mean((hypothesis - y_train) ** 2)
# cost로 H(x) 개선
optimizer.zero_grad()
cost.backward()
optimizer.step()
print('Epoch {:4d}/{} hypothesis: {} Cost: {:.6f}'.format(
epoch, nb_epochs, hypothesis.squeeze().detach(), cost.item()
))
nn.Module로 구현하는 선형 회귀
- 파이토치에서 이미 구현되어 제공되고 있는 함수를 불러오는 것으로 더 쉽게 선형 회귀모델 구현
- 선형 회귀 모델은 nn.Linear()라는 함수
- 평균 제곱오차는 nn.functional.mse_loss()라는 함수로 구현
1. 도구 임포트 및 시드 고정
# 도구 임포트 및 시드 고정
import torch
import torch.nn as nn
import torch.nn.functional as F
torch.manual_seed(1)
2. 데이터 선언
- y = 2x를 가정한 상태에서 만들어진 데이터로 정답이 W = 2, b = 0임을 알고 있음
- 모델이 W와 b의 값을 제대로 찾아내도록 하는 것이 목표
x_train = torch.FloatTensor([[1], [2], [3]])
y_train = torch.FloatTensor([[2], [4], [6]])
3. 모델 생성
- nn.Linear()는 입력의 차원, 출력의 차원을 인수로 받음
# 모델을 선언 및 초기화. 단순 선형 회귀이므로 input_dim=1, output_dim=1.
model = nn.Linear(1,1)
4. 생성한 모델의 가중치 W와 편향 b 확인
- model.parameters()라는 함수를 사용해 출력 가능
print(list(model.parameters()))
- 첫번째 값이 W, 두번째 값이 b에 해당, 두 값 모두 랜덤 초기화, 두 값 모두 학습의 대상이므로 requires_grad = True로 되어져 있는 것을 확인 가능
5. 옵티마이저 정의
- model.parameters()를 사용해 W와 b를 전달, 학습률(lr 은 0.01로 정의)
# optimizer 설정. 경사 하강법 SGD를 사용하고 learning rate를 의미하는 lr은 0.01
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
6. 모델 학습
# 전체 훈련 데이터에 대해 경사 하강법을 2,000회 반복
nb_epochs = 2000
for epoch in range(nb_epochs+1):
# H(x) 계산
prediction = model(x_train)
# cost 계산
cost = F.mse_loss(prediction, y_train) # <== 파이토치에서 제공하는 평균 제곱 오차 함수
# cost로 H(x) 개선하는 부분
# gradient를 0으로 초기화
optimizer.zero_grad()
# 비용 함수를 미분하여 gradient 계산
cost.backward() # backward 연산
# W와 b를 업데이트
optimizer.step()
if epoch % 100 == 0:
# 100번마다 로그 출력
print('Epoch {:4d}/{} Cost: {:.6f}'.format(
epoch, nb_epochs, cost.item()
))
7. 모델 테스트
- x 에 임의의 값 4를 넣어 모델이 예측하는 y값 확인
# 임의의 입력 4를 선언
new_var = torch.FloatTensor([[4.0]])
# 입력한 값 4에 대해서 예측값 y를 리턴받아서 pred_y에 저장
pred_y = model(new_var) # forward 연산
# y = 2x 이므로 입력이 4라면 y가 8에 가까운 값이 나와야 제대로 학습이 된 것
print("훈련 후 입력이 4일 때의 예측값 :", pred_y)
8. 학습 후의 W와 b값 출력
print(list(model.parameters()))
- H(x) 식에 입력 x로부터 예측된 y를 얻는 것을 forward 연산이라고 함
- 학습 전, prediction = model(x_trian)은 x_train으로부터 예측값을 리턴하므로 forward 연산임
- 학습 후, pred_y = model(new_var)은 임의의 값 new_var로부터 예측값을 리턴하므로 forward 연산
- 학습 과정에서 비용 함수를 미분하여 기울기를 구하는 것을 backward 연산이라고 함
- cost.backward()는 비용 함수로부터 기울기를 구하라는 의미이며 backward 연산임
다중 선형 회귀 구현
1. 도구 임포트 및 시드 고정
# 도구 임포트 및 시드 고정
import torch
import torch.nn as nn
import torch.nn.functional as F
torch.manual_seed(1)
2. 데이터 선언, 3개의 x로부터 하나의 y를 예측
# 데이터 선언, 3개의 x로부터 하나의 y를 예측
x_train = torch.FloatTensor([[73, 80, 75],
[93, 88, 93],
[89, 91, 90],
[96, 98, 100],
[73, 66, 70]])
y_train = torch.FloatTensor([[152], [185], [180], [196], [142]])
3. 선형 회귀 모델 구현
- nn.Linear() 사용
# 선형 회귀 모델 구현
# 모델을 선언 및 초기화. 다중 선형 회귀이므로 input_dim=3, output_dim=1.
model = nn.Linear(3,1)
4. 모델 파라미터 가중치 w와 편향 b 확인
print(list(model.parameters()))
5. 옵티마이저 정의
- 학습률(lr)은 0.00001로 설정, 파이썬 코드 1e-5로 표기 가능
- 0.01로 하지 않는 이유는 기울기가 발산하기 때문
optimizer = torch.optim.SGD(model.parameters(), lr=1e-5)
6. 학습 진행
nb_epochs = 2000
for epoch in range(nb_epochs+1):
# H(x) 계산
prediction = model(x_train)
# model(x_train)은 model.forward(x_train)와 동일함.
# cost 계산
cost = F.mse_loss(prediction, y_train) # <== 파이토치에서 제공하는 평균 제곱 오차 함수
# cost로 H(x) 개선하는 부분
# gradient를 0으로 초기화
optimizer.zero_grad()
# 비용 함수를 미분하여 gradient 계산
cost.backward()
# W와 b를 업데이트
optimizer.step()
if epoch % 100 == 0:
# 100번마다 로그 출력
print('Epoch {:4d}/{} Cost: {:.6f}'.format(
epoch, nb_epochs, cost.item()
))
7. 임의의 입력[ 73, 80, 75 ] 값으로 예측값 확인
# 3개의 w와 b의 값 최적화 확인
# 임의의 입력 [73, 80, 75]를 선언
new_var = torch.FloatTensor([[73, 80, 75]])
# 입력한 값 [73, 80, 75]에 대해서 예측값 y를 리턴받아서 pred_y에 저장
pred_y = model(new_var)
print("훈련 후 입력이 73, 80, 75일 때의 예측값 :", pred_y)
8. 학습 후의 w와 b의 값 확인
# 학습 후의 w와 b의 값 확인
print(list(model.parameters()))
클래스로 파이토치 모델 구현
단순 선형 회귀 클래스 구현
# 도구 임포트
import torch
import torch.nn as nn
import torch.nn.functional as F
# 랜덤 시드 고정
torch.manual_seed(1)
# 데이터 로드
x_train = torch.FloatTensor([[1], [2], [3]])
y_train = torch.FloatTensor([[2], [4], [6]])
# 모델 클래스 생성
class LinearRegressionModel(nn.Module): # torch.nn.Module을 상속받는 파이썬 클래스
def __init__(self):
super().__init__()
self.linear = nn.Linear(1, 1) # 단순 선형 회귀이므로 input_dim=1, output_dim=1.
def forward(self, x):
return self.linear(x)
# 모델 객체 생성
model = LinearRegressionModel()
# optimizer 설정. 경사 하강법 SGD를 사용하고 learning rate를 의미하는 lr은 0.01
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 전체 훈련 데이터에 대해 경사 하강법을 2,000회 반복
nb_epochs = 2000
for epoch in range(nb_epochs+1):
# H(x) 계산
prediction = model(x_train)
# cost 계산
cost = F.mse_loss(prediction, y_train) # <== 파이토치에서 제공하는 평균 제곱 오차 함수
# cost로 H(x) 개선하는 부분
# gradient를 0으로 초기화
optimizer.zero_grad()
# 비용 함수를 미분하여 gradient 계산
cost.backward() # backward 연산
# W와 b를 업데이트
optimizer.step()
if epoch % 100 == 0:
# 100번마다 로그 출력
print('Epoch {:4d}/{} Cost: {:.6f}'.format(
epoch, nb_epochs, cost.item()
))
다중 선형 회귀 클래스 구현
# 도구 임포트
import torch
import torch.nn as nn
import torch.nn.functional as F
# 랜덤 시드 고정
torch.manual_seed(1)
# 데이터 로드
x_train = torch.FloatTensor([[73, 80, 75],
[93, 88, 93],
[89, 91, 90],
[96, 98, 100],
[73, 66, 70]])
y_train = torch.FloatTensor([[152], [185], [180], [196], [142]])
# 모델 클래스 생성
class MultivariateLinearRegressionModel(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(3, 1) # 다중 선형 회귀이므로 input_dim=3, output_dim=1.
def forward(self, x):
return self.linear(x)
# 모델 객체 생성
model = MultivariateLinearRegressionModel()
# optimizer 설정. 경사 하강법 SGD를 사용하고 learning rate를 의미하는 lr은 0.01
optimizer = torch.optim.SGD(model.parameters(), lr=1e-5)
# 전체 훈련 데이터에 대해 경사 하강법을 2,000회 반복
nb_epochs = 2000
for epoch in range(nb_epochs+1):
# H(x) 계산
prediction = model(x_train)
# model(x_train)은 model.forward(x_train)와 동일함.
# cost 계산
cost = F.mse_loss(prediction, y_train) # <== 파이토치에서 제공하는 평균 제곱 오차 함수
# cost로 H(x) 개선하는 부분
# gradient를 0으로 초기화
optimizer.zero_grad()
# 비용 함수를 미분하여 gradient 계산
cost.backward()
# W와 b를 업데이트
optimizer.step()
if epoch % 100 == 0:
# 100번마다 로그 출력
print('Epoch {:4d}/{} Cost: {:.6f}'.format(
epoch, nb_epochs, cost.item()
))
미치 배치와 데이터 로드(Mini Batch and Data Load)
데이터 로드와 미니 배치 경사 하강법(Minibatch Gradient Descent) 학습
미니 배치를 사용하는 이유
- 데이터가 수십만개 이상이라면 전체 데이터에 대해 경사 하강법을 수행하는 것은 매우 느리고, 많은 계산량을 필요로 함
- 이 때문에 전체 데이터를 더 작은 단위로 나누어서 해당 단위로 하급하는 개념 등장
배치 크기(batch size)
- 미니 배치의 개수는 미니 배치의 크기를 몇으로 하느냐에 따라 달라짐, 미니 배치의 크기를 batch size라고 함
- 배치 경사 하강법 : 전체 데이터에 대해서 한 번에 경사 하강법을 수행하는 방법
- 미니 배치 경사 하강법 : 미니 배치 단위로 경사 하강법을 수행
- 배치 크기는 보통 2의 제곱수를 사용. CPU와 GPU 메모리가 2의 배수이므로 배치크기가 2의 제곱수일 경우 데이터 송수신의 효율을 높일 수 있음
배치 경사 하강법은 전체 데이터를 사용하므로 가중치 값이 최적값에 수렴하는 과정이 매우 안정적이지만, 많은 계산량을 필요오 함, 미니 배치 경사 하강법은 전체 데이터의 일부만을 보고 수행하므로 최적값으로 수렴하는 과정에서 값을 조금 헤매기도 하지만 훈련 속도가 빠름
이터레이션(Iteration)
- 이터레이션은 한번의 에포크 내에서 이루어지는 매개변수인 가중치 W와 b의 업데이트 횟수
- 전체 데이터가 2,000일 때 배치 크기를 200으로 한다면 이터레이션의 수는 총 10개이며, 이는 하나의 에포크 당 매개변수 업데이트가 10번 이루어짐을 의미
데이터 로드
파이토치 에서는 데이터를 쉽게 다룰 수 있는 도구로 데이터셋(Dataset)과 데이터로더(DataLoader)를 제공, 이를 사용하면 미니 배치 학습, 데이터 셔플, 병렬 처리까지 간단히 수행 가능
1. 도구 임포트
# 필요 도구 임포트
import torch
import torch.nn as nn
import torch.nn.functional as F
2. TensorDataset 과 DataLoader 를 임포트
# TensorDataset 과 DataLoader를 임포트
from torch.utils.data import TensorDataset # 텐서데이터셋
from torch.utils.data import DataLoader # 데이터로더
3. 텐서 형태로 데이터 정의
# TenserDataset은 기본적으로 텐서를 입력으로 받음, 텐서 형태로 데이터 정의
x_train = torch.FloatTensor([[73, 80, 75],
[93, 88, 93],
[89, 91, 90],
[96, 98, 100],
[73, 66, 70]])
y_train = torch.FloatTensor([[152], [185], [180], [196], [142]])
4. 정의한 데이터를 dataset으로 저장
# 정의한 데이터를 TensorDataset의 입력으로 사용하고 dataset으로 저장
dataset = TensorDataset(x_train, y_train)
5. 데이터 로더 사용
# 데이터셋을 생성한 후 데이터로더를 사용가능, 데이터로더는 기본적으로 2개의 인자(데이터셋, 미니 배치의 크기-통상 2의 배수)를 받음
# 추가적으로 자주 사용되는 인자로 shuffle이 있음, 이는 Epoch마다 데이터셋을 섞어서 모델이 데이터셋에 익숙해지는 것을 방지하여 성능 향상에 도움을 줌
dataloader = DataLoader(dataset, batch_size=2, shuffle=True)
6. 모델과 옵티마이저 설정
model = nn.Linear(3,1)
optimizer = torch.optim.SGD(model.parameters(), lr=1e-5)
7. 모델 학습
nb_epochs = 20
for epoch in range(nb_epochs + 1):
for batch_idx, samples in enumerate(dataloader):
# print(batch_idx)
# print(samples)
x_train, y_train = samples
# H(x) 계산
prediction = model(x_train)
# cost 계산
cost = F.mse_loss(prediction, y_train)
# cost로 H(x) 계산
optimizer.zero_grad()
cost.backward()
optimizer.step()
print('Epoch {:4d}/{} Batch {}/{} Cost: {:.6f}'.format(
epoch, nb_epochs, batch_idx+1, len(dataloader),
cost.item()
))
8. 예측 값 확인
# 모델의 입력으로 임의의 값을 넣어 예측값 확인
# 임의의 입력 [73, 80, 75]를 선언
new_var = torch.FloatTensor([[73, 80, 75]])
# 입력한 값 [73, 80, 75]에 대해서 예측값 y를 리턴받아서 pred_y에 저장
pred_y = model(new_var)
print("훈련 후 입력이 73, 80, 75일 때의 예측값 :", pred_y)
커스텀 데이터셋(Custom Dataset)
기본 뼈대
# 커스텀 데이터셋을 만들 때, 기본적인 뼈대
class CustomDataset(torch.utils.data.Dataset):
def __init__(self):
# 데이터셋의 전처리를 해주는 부분
self.x_data = [[73, 80, 75],
[93, 88, 93],
[89, 91, 90],
[96, 98, 100],
[73, 66, 70]]
self.y_data = [[152], [185], [180], [196], [142]]
def __len__(self):
# 데이터셋의 길이. 즉, 총 샘플의 수를 적어주는 부분
return len(self.x_data)
def __getitem__(self, idx):
# 데이터셋에서 특정 1개의 샘플을 가져오는 함수
x = torch.FloatTensor(self.x_data[idx])
y = torch.FloatTensor(self.y_data[idx])
return x, y
커스텀 데이터셋으로 선형 회귀 구현
# 도구 임포트
import torch
import torch.nn.functional as F
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
# Dataset 상속
class CustomDataset(Dataset):
def __init__(self):
self.x_data = [[73, 80, 75],
[93, 88, 93],
[89, 91, 90],
[96, 98, 100],
[73, 66, 70]]
self.y_data = [[152], [185], [180], [196], [142]]
# 총 데이터의 개수를 리턴
def __len__(self):
return len(self.x_data)
# 인덱스를 입력받아 그에 맵핑되는 입출력 데이터를 파이토치의 Tensor 형태로 리턴
def __getitem__(self, idx):
x = torch.FloatTensor(self.x_data[idx])
y = torch.FloatTensor(self.y_data[idx])
return x, y
# 데이터셋, 데이터로더 객체 생성
dataset = CustomDataset()
dataloader = DataLoader(dataset, batch_size=2, shuffle=True)
# 모델, 옵티마이저 설정
model = torch.nn.Linear(3,1)
optimizer = torch.optim.SGD(model.parameters(), lr=1e-5)
# 훈련 진행
nb_epochs = 20
for epoch in range(nb_epochs + 1):
for batch_idx, samples in enumerate(dataloader):
# print(batch_idx)
# print(samples)
x_train, y_train = samples
# H(x) 계산
prediction = model(x_train)
# cost 계산
cost = F.mse_loss(prediction, y_train)
# cost로 H(x) 계산
optimizer.zero_grad()
cost.backward()
optimizer.step()
print('Epoch {:4d}/{} Batch {}/{} Cost: {:.6f}'.format(
epoch, nb_epochs, batch_idx+1, len(dataloader),
cost.item()
))
훈련 결과 확인
# 훈련 결과 확인
# 임의의 입력 [73, 80, 75]를 선언
new_var = torch.FloatTensor([[73, 80, 75]])
# 입력한 값 [73, 80, 75]에 대해서 예측값 y를 리턴받아서 pred_y에 저장
pred_y = model(new_var)
print("훈련 후 입력이 73, 80, 75일 때의 예측값 :", pred_y)
참고:
https://wikidocs.net/book/2788
PyTorch로 시작하는 딥 러닝 입문
이 책은 딥 러닝 프레임워크 PyTorch를 사용하여 딥 러닝에 입문하는 것을 목표로 합니다. 이 책은 2019년에 작성된 책으로 비영리적 목적으로 작성되어 출판 ...
wikidocs.net
'AI > PyTorch' 카테고리의 다른 글
| PyTorch #소프트맥스 회귀(Softmax Regression) (0) | 2022.03.24 |
|---|---|
| PyTorch #로지스틱 회귀(Logistic Regression) (0) | 2022.03.23 |
| PyTorch 텐서 조작 #뷰 #스퀴즈 #언스퀴즈 #타입 캐스팅 #텐서 연결 (0) | 2022.03.22 |
| PyTorch 텐서 조작 #텐서 선언 #곱셈 #평균 #덧셈 #최대 #아그맥스 (0) | 2022.03.22 |
| PyTorch #파이토치란? #패키지 기본 구성 (0) | 2022.03.22 |



