1) 뷰(View)
- 원소의 수를 유지하면서 텐서의 크기 변경
- 파이토치 텐서의 뷰(view)는 넘파이에서 리쉐이프(Reshape)와 같은 역할
- 텐서의 크기(Shape)를 변경
- 3차원 텐서 생성
# torch 임포트
import torch
# numpy 임포트
import numpy as np
# 3차원 텐서 생성
t = np.array([[[0, 1, 2],
[3, 4, 5]],
[[6, 7, 8],
[9, 10, 11]]])
ft = torch.FloatTensor(t)
# ft의 크기 확인
print(ft.shape)
- 3차원 텐서에서 2차원 텐서로 변경
# ft라는 텐서를 (?,3)의 크기로 변경
print(ft.view([-1, 3]))
print(ft.view([-1, 3]).shape)
view([-1,3]) 이 가지는 의미. -1은 첫번째 차원은 사용자가 잘 모르겠으니 파이토치 알아서 해~ 라는 의미, 3은 두번째 차원의 길이는 3을 가지도록 하라는 의미. 다시 말해 3차원 텐서를 2차원 텐서로 변경하되 (?,3)의 크기로 변경하라는 의미.
규칙.
view는 기본적으로 변경 전과 변경 후의 텐서 안의 원소의 개수가 유지되어야 한다.
파이토치의 view는 사이즈가 -1로 설정되면 다른 차원으로부터 해당 값을 유추한다.
- 3차원 텐서의 크기 변경
print(ft.view(-1, 1, 3))
print(ft.view(-1, 1, 3).shape)
2) 스퀴즈(Squeeze) - 1인 차원을 제거
# (3,1) 텐서 선언
ft = torch.FloatTensor([[0], [1], [2]])
print(ft)
print(ft.shape)
# 두 번째 차원이 1이므로 squeeze를 사용하면 (3,) 의 크기를 가지는 텐서로 변환된다.
print(ft.squeeze())
print(ft.squeeze().shape)
3) 언스퀴즈(Unsqueeze) - 특정 위치에 1인 차원을 추가.
- 1차원 텐서 생성
# 언스퀴즈는 스퀴즈와 정반대로 특정 위치에 1인 차원을 추가할 수 있다.
ft = torch.Tensor([0, 1, 2])
print(ft.shape)
- 첫 번째 차원에 1인 차원을 추가, 첫 번째 차원의 인덱스를 의미하는 숫자 0을 인자로 넣는다.
# 첫 번째 차원에 1인 차원을 추가, 첫번째 차원의 인덱스를 의미하는 숫자 0을 인자로 넣는다.
print(ft.unsqueeze(0)) # 인덱스가 0부터 시작하므로 0은 첫번째 차원을 의미한다.
print(ft.unsqueeze(0).shape)
- 동일한 연산을 view로 구현
# 동일한 연산을 view로 구현
print(ft.view(1, -1))
print(ft.view(1, -1).shape)
- unsqueeze 인자로 1을 넣음, 두 번째 차원에 1을 추가하겠다는 의미.
# unsqueeze 인자로 1을 넣음. 두 번째 차원에 1을 추가하겠다는 의미.
print(ft.unsqueeze(1))
print(ft.unsqueeze(1).shape)
- unsqueeze 인자로 -1을 넣음, -1은 인덱스 상으로 마지막 차원을 의미함.
- 현재 텐서의 경우 1을 넣은 경우와 -1을 넣은 경우 결과가 같다.
# unsqueeze 인자로 -1을 넣음. -1은 인덱스 상으로 마지막 차원을 의미함. 현재 텐서의 경우 1을 넣은 경우와 -1을 넣은 경우 결과가 같음
print(ft.unsqueeze(-1))
print(ft.unsqueeze(-1).shape)
view(), squeeze(), unsqueeze()는 텐서의 원소 수를 그대로 유지하면서 모양과 차원을 조절함
4) 타입 캐스팅(Type Casting)
- 텐서에는 자료형이 존재, 각 데이터형별로 정의, 예를 들어 32비트 부동 소수점은 touch.FloatTensor, 64비트의 부호 있는 정수는 touch.LongTensor를 사용, GPU연산을 위한 자료형도 존재. touch.cuda.FloatTensor
이 같은 자료형을 변환하는 것을 타입 캐스팅이라고 함
- long 타입의 텐서 선언
# long 타입의 It라는 텐서 선언
lt = torch.LongTensor([1, 2, 3, 4])
print(lt)
- float 형으로 타입 캐스팅
# float 형으로 타입 캐스팅
print(lt.float())
- Byte 타입의 bt 라는 텐서 선언
# Byte 타입의 bt라는 텐서 선언
bt = torch.ByteTensor([True, False, False, True])
print(bt)
- long 타입과 float 타입 텐서로 타입 캐스팅
# .long() 타입과 .float() 타입 텐서로 타입 캐스팅
print(bt.long())
print(bt.float())
5) 텐서 연결(concatenate)
- 두 텐서를 연결 하는 방법에 대해 알아본다.
- (2, 2) 크기의 텐서 두개 선언
# (2, 2) 크기의 텐서 두 개 선언
x = torch.FloatTensor([[1, 2], [3, 4]])
y = torch.FloatTensor([[5, 6], [7, 8]])
print(x)
print(y)
- torch.cat([])을 통해 두 텐서를 연결
- torch.cat은 어느 차원을 늘릴 것인지 인자로 줄 수 있음, dim = 0 을 인자로 주면 첫 번째 차원을 늘림
# 두 텐서를 torch.cat([])를 통해 연결
# 연결 방법은 한 가지만 있는 것이 아니고, torch.cat은 어느 차원을 늘릴 것인지 인자로 줄 수 있음. dim=0을 인자로 주면 첫 번째 차원을 늘림
print(torch.cat([x,y], dim = 0))
- dim = 1로 인자를 줘서 두 번째 차원을 늘림
# dim = 1로 인자를 줘서 두 번째 차원을 늘림
print(torch.cat([x,y], dim = 1))
6) 스택킹(Stacking)
- 연결(concatenate)를 하는 다른 방법으로 스택킹(Stacking)이 있음, 영어로 쌓는다는 의미로 스택킹은 많은 연산을 포함하고 있음
- 크기가 (2,)인 동일한 3개의 벡터 선언
# 크기가 (2,)로 모두 동일한 3개의 벡터 선언
x = torch.FloatTensor([1, 4])
y = torch.FloatTensor([2, 5])
z = torch.FloatTensor([3, 6])
print(x)
print(y)
print(z)
- torch.stack를 통해 3개의 백터를 모두 스택킹
# torch.stack를 통해 3개의 벡터를 모두 스택킹
print(torch.stack([x,y,x]))
# 스택킹은 많은 연산을 한번에 축약한 것으로, 위 작은 아래의 코드와 동일한 연산을 수행
print(torch.cat([x.unsqueeze(0), y.unsqueeze(0), z.unsqueeze(0)], dim=0))
- 스택킹에 dim을 인자로 전달 가능, dim = 1을 인자로 주면 두 번째 차원이 증가하도록 쌓으라는 의미
# 스택킹에 dim을 인자로 전달 가능, dim = 1을 인자로 주면 두 번째 차원이 증가하도록 쌓으라는 의미
print(torch.stack([x,y,z], dim = 1))
print(torch.cat([x.unsqueeze(1), y.unsqueeze(1), z.unsqueeze(1)], dim=1))
7) ones_like, zeros_like
- 0으로 채워진 텐서와 1로 채워진 텐서
- (2,3) 텐서 선언
# (2,3) 텐서 선언
x = torch.FloatTensor([[0, 1, 2], [2, 1, 0]])
print(x)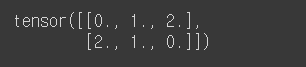
- ones_like : 동인한 크기(shape)지만 1로만 값이 채워진 텐서 생성
# ones_like를 하면 동일한 크기(shape)지만 1로만 값이 채워진 텐서 생성
print(torch.ones_like(x))
- zeros_like : 동인한 크기(shape)지만 0으로만 값이 채워진 텐서 생성
# zeros_like를 하면 동일한 크기(shape)지만 0으로만 값이 채워진 텐서 생성
print(torch.zeros_like(x))
8) 덮어쓰기 연산(In-Place Operation)
- 곱하기 연산을 하더라도 기존의 x값은 저장되지 않음으로 값이 변하지 않는다.
- 하지만 연산 뒤에 _를 붙이면 기존의 값을 덮어쓴다.
# 연산 뒤에 _를 붙이면 기존의 값을 덮어쓴다.
print(x.mul_(2.)) # 곱하기 2를 수행한 결과를 변수 x에 값을 저장하면서 결과를 출력
print(x) # 기존의 값 출력
참고:
https://wikidocs.net/book/2788
PyTorch로 시작하는 딥 러닝 입문
이 책은 딥 러닝 프레임워크 PyTorch를 사용하여 딥 러닝에 입문하는 것을 목표로 합니다. 이 책은 2019년에 작성된 책으로 비영리적 목적으로 작성되어 출판 ...
wikidocs.net
'AI > PyTorch' 카테고리의 다른 글
| PyTorch #소프트맥스 회귀(Softmax Regression) (0) | 2022.03.24 |
|---|---|
| PyTorch #로지스틱 회귀(Logistic Regression) (0) | 2022.03.23 |
| PyTorch #선형 회귀(Linear Regression) (0) | 2022.03.23 |
| PyTorch 텐서 조작 #텐서 선언 #곱셈 #평균 #덧셈 #최대 #아그맥스 (0) | 2022.03.22 |
| PyTorch #파이토치란? #패키지 기본 구성 (0) | 2022.03.22 |



