크롤링 한 데이터를 다양한 파일의 형태로 저장
1. selenium 으로 크롬 브라우저를 열고, 원하는 데이터를 추출.
크롤링 할 사이트 : https://aihub.or.kr/
홈 | AI 허브
AI 허브는 AI 기술 및 제품·서비스 개발에 필요한 AI 인프라(AI 데이터, AI SW API, 컴퓨팅 자원)를 지원함으로써 누구나 활용하고 참여하는 AI 통합 플랫폼입니다.
aihub.or.kr
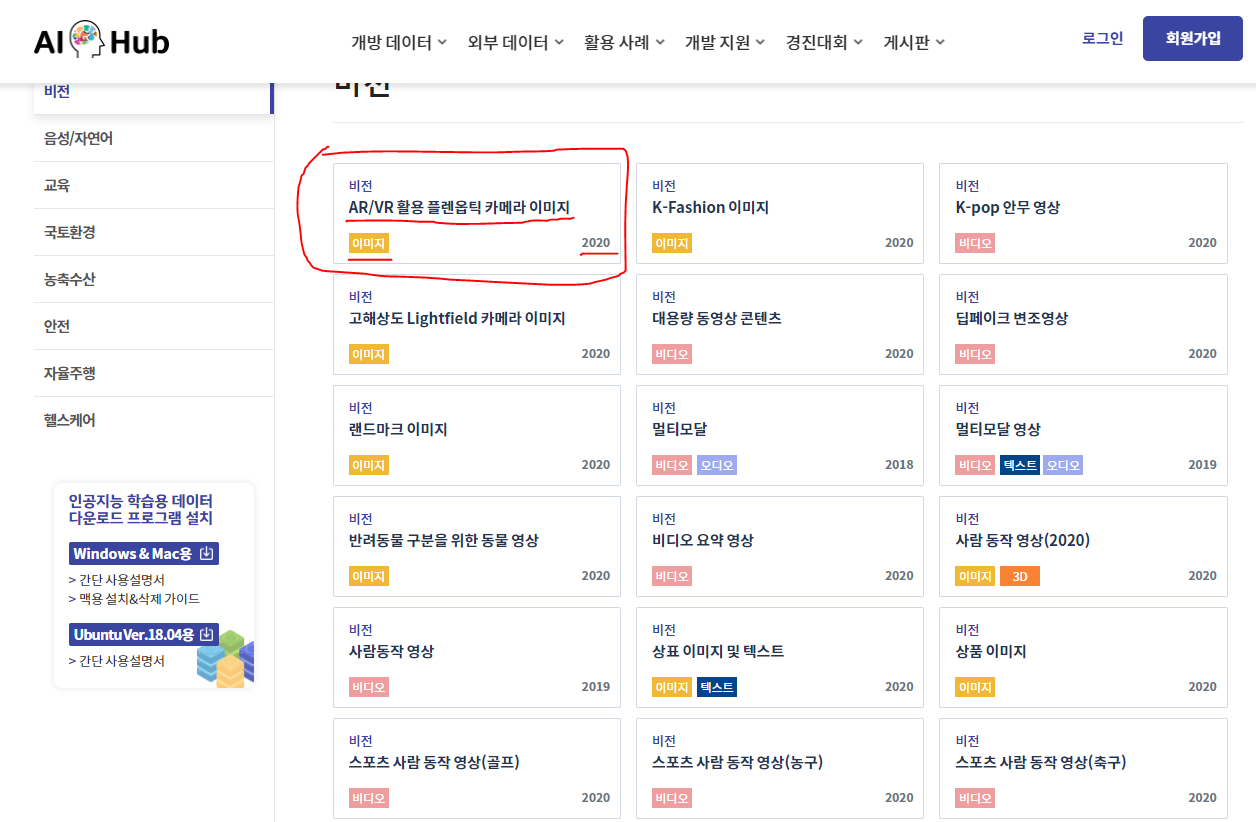
서브페이지 중 개방데이터 -> 비전 탭에서 데이터를 추출할 예정이며 빨간 표시된 박스 안의 타이틀 부분, 속성태그, 년도 순으로 총 3개의 데이터를 추출
1. 주피터 노트북 열고 필요한 모듈 불러오기
from bs4 import BeautifulSoup #페이지 파싱용
from selenium import webdriver #브라우저 컨트롤용
import time
from selenium.webdriver.common.keys import Keys #키컨트롤용, 오늘은 사실 필요없음
import sys #파일로 저장하기 위한 모듈
2. 총 3개의 파일로 저장할 예정, txt파일은 f_name, csv파일은 fc_name, xlsx 파일은 fx_name으로 파일 이름 입력받기
f_name = "C:\\python_temp\\data\\"+input('검색 결과를 저장할 파일 이름을 지정하세요.\n(예:20210914_test.txt): ')
fc_name = "C:\\python_temp\\data\\"+input('검색 결과를 저장할 파일 이름을 지정하세요.\n(예:20210914_test.csv): ')
fx_name = "C:\\python_temp\\data\\"+input('검색 결과를 저장할 파일 이름을 지정하세요.\n(예:20210914_test.xls): ')검색 결과를 저장할 파일 이름을 지정하세요.
(예:20210914_test.txt): 20210914_test.txt
검색 결과를 저장할 파일 이름을 지정하세요.
(예:20210914_test.csv): 20210914_test.csv
검색 결과를 저장할 파일 이름을 지정하세요.
(예:20210914_test.xls): 20210914_test.xls
3. 크롬 드라이버를 사용, 웹 브라우저를 실행
#크롬 드라이버를 사용해서 웹 브라우저를 실행합니다.
path = "C:\python_temp\chromedriver.exe"
driver = webdriver.Chrome(path)
driver.get("https://aihub.or.kr/aihub-data/vision/about")
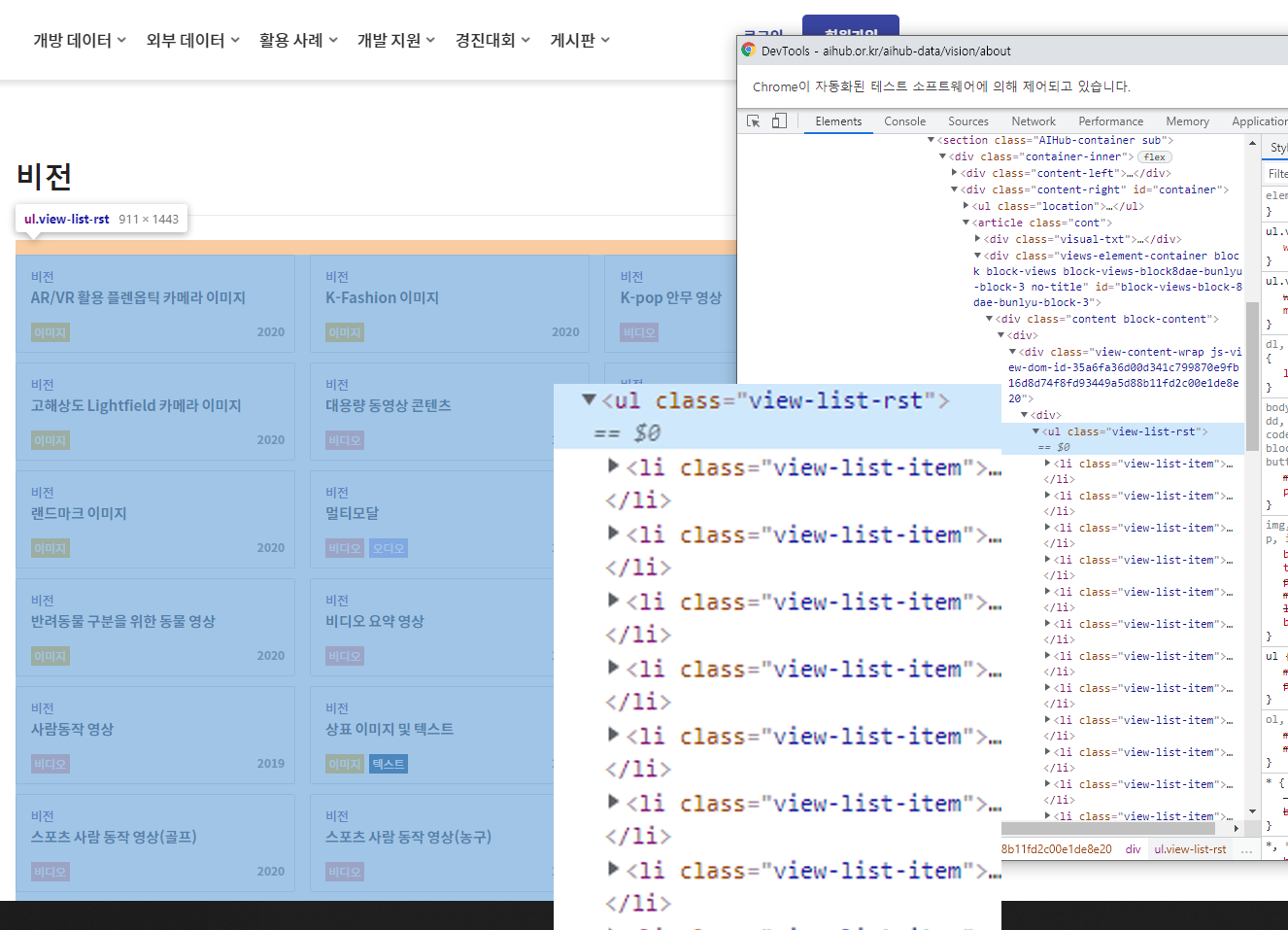
4. 크롬 브라우저 개발자 도구를 사용, 구조를 파악
- 대분류
tag : ul
class : view-list-rst
- 소분류
tag : li
class : view-list-item
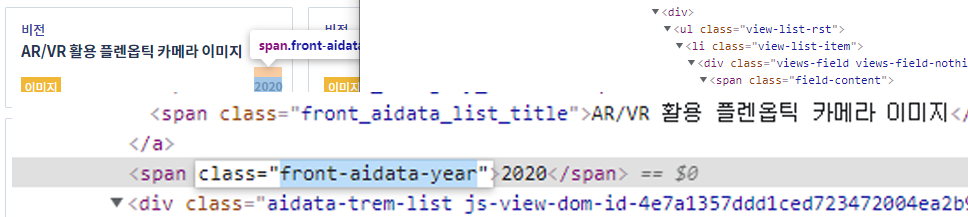
5. 구조 파악 2
- 타이틀
tag : span
class : front_aidata_list_title

- 속성 태그
tag : span
class : front_aidata_att

- 년도
tag : span
class : front-aidata-year
6. 파싱한 데이터에서 데이터 크롤링.
find
find_all
select
select_one
attrs
get_text
위 6개는 특히 연습 많이 해볼 것.
#현재 페이지에 있는 내용을 화면에 출력합니다.
time.sleep(1) #검색 결과가 다 나올 때 까지 1초 대기
full_html = driver.page_source#페이지 전체를 가져옴
soup = BeautifulSoup(full_html, 'html.parser')
content_list = soup.find('ul', 'view-list-rst').select('div > span')
no = 0
for i in content_list:
try:
contents = i.find('span', 'front_aidata_list_title').get_text()
except AttributeError:
continue
else:
no+=1
print("번호:", no)
print(contents)
try:
at_tag = i.find('div', 'item').get_text()
except AttributeError:
continue
else:
print(at_tag)
try:
date = i.find('span', 'front-aidata-year').get_text()
except AttributeError:
continue
else:
print(date)
print("-"*50,"\n")
2. 출력용 리스트를 위 결과 기준으로 생성하기 위해 데이터 출력 부분에 새로운 리스트를 만들고,
코드 실행
#현재 페이지에 있는 내용을 화면에 출력합니다.
time.sleep(1) #검색 결과가 다 나올 때 까지 1초 대기
full_html = driver.page_source#페이지 전체를 가져옴
soup = BeautifulSoup(full_html, 'html.parser')
content_list = soup.find('ul', 'view-list-rst').select('div > span')
#--------출력용 리스트 생성--------
no2 = []
contents2 = []
at_tag2 = []
date2 = []
#----------------------------------
no = 0
for i in content_list:
try:
contents = i.find('span', 'front_aidata_list_title').get_text()
except AttributeError:
continue
else:
no+=1
print("번호:", no)
print("타이틀:", contents)
no2.append(no)#출력용
contents2.append(contents)#출력용
try:
at_tag = i.find('div', 'item').get_text()
except AttributeError:
continue
else:
print("태그:", at_tag)
at_tag2.append(at_tag)#출력용
try:
date = i.find('span', 'front-aidata-year').get_text()
except AttributeError:
continue
else:
print("년도:",date)
date2.append(date)#출력용
print("-"*50,"\n")
3. 만들어진 데이터로 파일 생성
1. 판다스 모듈 및 xlwt 모듈 설치
!pip install pandas
!pip install xlwt#엑셀파일 저장을 위한 모듈
2. 화면 출력 결과를 표(데이터프레임)형태로 만듬
# 분리 수집된 데이터를 데이터 프레임으로 만들어서 csv, xls 형식으로 저장합니다.
# 출력결과를 표(데이터프레임) 형태로 만듭니다.
import pandas as pd
import xlwt #엑셀로 저장을 위해
aihub_box = pd.DataFrame() #aihub_box을 데이터프레임 객체로 생성
#컬럼명 생성뒤 위에서 만든 리스트를 저장
aihub_box['번호'] = no2
aihub_box['타이틀'] = contents2
aihub_box['태그'] = at_tag2
aihub_box['년도'] = date2
3. 파일 저장 (csv, xlsx)
#csv 형태로 저장하기
aihub_box.to_csv(fc_name, encoding='utf-8-sig')#지정된 구문 형태
print('csv 파일 저장 경로 : %s'%fc_name)
#xls 형태로 저장하기
aihub_box.to_excel(fx_name)
print('xls 파일 저장 경로 : %s'%fx_name)

4. 파일 저장(txt)
#txt파일로 저장
orig_stdout = sys.stdout
time.sleep(1)
f = open(f_name, 'a', encoding = 'UTF-8')
sys.stdout = f
time.sleep(1)
no = 0
for i in content_list:
try:
contents = i.find('span', 'front_aidata_list_title').get_text()
except AttributeError:
continue
else:
no+=1
print("번호:", no)
print("타이틀:", contents)
try:
at_tag = i.find('div', 'item').get_text()
except AttributeError:
continue
else:
print("태그:", at_tag)
try:
date = i.find('span', 'front-aidata-year').get_text()
except AttributeError:
continue
else:
print("년도:",date)
print("-"*50,"\n")
sys.stdout = orig_stdout
f.close()
'AI > StudyNote' 카테고리의 다른 글
| Python #웹크롤링 #요약 정보 추출 후 저장 (0) | 2021.09.15 |
|---|---|
| Python #엑셀다루기 (0) | 2021.09.14 |
| Python #웹크롤링 #xpath #txt파일저장 (0) | 2021.09.13 |
| Python #웹 제어 #selenium 모듈 (0) | 2021.09.10 |
| Python #웹크롤링 #BeautifulSoup 모듈 (0) | 2021.09.10 |



